

















グローバル ジャイアントテックの資本が入っているから「未来が見える」

夏目 岡田さんは日本でAIが注目されていない時期からAIの社会実装に奔走されてきました。そんなご経歴だから「ミッションクリティカルな業務で使えるAIを開発すべき」と、将来が見えたんですか?
岡田 そういう部分もあるかもしれません。私がコンピューターを学び始めた小学生の頃、友人に「オタクになるの?」とからかわれたこともありましたが(笑)、私は「いやどうみても今後はコンピューターの時代でしょ」と言っていました。それくらい先進性のあることをやるのが好きなんでしょう。
しかし、先が見えた理由としてはもっと多くのものがあります。ABEJA設立後、いち早くAIの可能性に気づいた方たちから、多くのエンタープライズ企業の幹部をご紹介いただきました。そして、大企業の幹部の方々とAIをどの業務に実装していくべきかディスカッションをする中で「うちの現場では精度99%なんかじゃ話にならないよ」といった、時に手厳しく、時に耳が痛いご指摘をいただきました。それ以来、諦めず続けてきたことが、今、花開き始めているんです。
また、我々ABEJAは2017年にNVIDIAから、2018年にはGoogleから出資を受けています。業務の中で同社のエンジニアチームやリサーチチームなどと議論する機会に恵まれ、結果、我々は世界最先端の情報に触れることができています。
夏目 とすると「次」も準備されているとか?
岡田 もちろんです。例えば我々は2023年3月から、生成AIのひとつである大規模言語モデル(Large Language Model、以下「LLM」)を、「ABEJA LLM Series」として商用化しています。
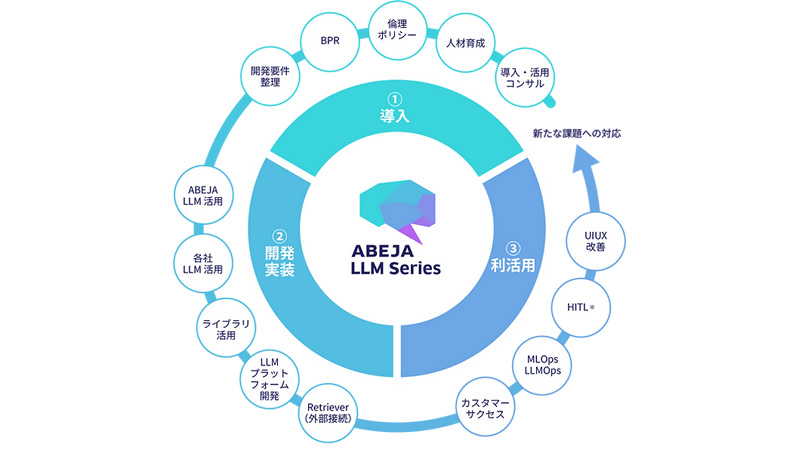 「ABEJA LLM Series」では、LLMのビジネス導入においてこれまでに得たDX/AIの導入ナレッジや、ABEJA独自のLLM研究開発ナレッジを基に、貴社ビジネスへのLLMの「導入」、「開発・実装」、「利活用」を一気通貫で推進する。(ABEJAHPより画像引用)
「ABEJA LLM Series」では、LLMのビジネス導入においてこれまでに得たDX/AIの導入ナレッジや、ABEJA独自のLLM研究開発ナレッジを基に、貴社ビジネスへのLLMの「導入」、「開発・実装」、「利活用」を一気通貫で推進する。(ABEJAHPより画像引用)
夏目 生成AIということは、文章の作成とか要約とか、質問に対する回答とか、そういうことが可能なAIですね?
岡田 はい。2018年にGoogleが「BERT」※を発表した時、我々は「今後は商用利用ニーズが高まる」と考え、自社でも研究開発を進めてきました。そして2022年7月には、最大130億パラメーターを持つ日本語に特化したモデルの一部をオープン化しています。加えて、プライバシー保護や情報漏洩などのリスクマネジメントに対応させています。ChatGPTなどのオープンなAPIを利用する場合、入力したデータはAIの学習データとしても取り扱われるため、個人情報や機密情報の漏洩リスクを負ってしまいます。このため、業務利用を原則禁止とする企業も増えていますが、当社のLLMならハンドリングが可能です。
夏目 LLMが普及すると世界はどう変わるんですか?
岡田 ホワイトワーカーの業務の一部をAIが代替可能になると言われています。
医師や弁護士などの仕事は膨大な知識を必要とします。しかし、1人の人間が蓄えられる知識の量は、AIに比べて少ないんです。そこで、こういった分野をAIに学習させれば、より速くより正確な回答が期待できるようになります。「知的生産性の最大化」が果たせるんです。
夏目 例えば病気の診断も、LINEで症状や体温を伝えればできるようになるとか?
岡田 できます。ただし、診断には詳細な検査も必要ですし、時には患者さんの気持ちに寄り添うことも大切でしょう。これらはお医者様でなければできません。私は、AIが「こんな症状が考えられるのでこの検査が必要です」などと対応をして医師の方の負担を減らす未来を想像しています。
またLLMは、ロボットの進化によって社会に大きなインパクトを与えると考えられます。(第2回に続く)
※BERT:Bidirectional Encoder Representations from Transformersを略した自然言語処理モデルであり、2018年10月にGoogle社のJacob Devlin氏らが発表したことで、大きな注目を集めた。最大の特徴として、「文脈を読めるようになったこと」が挙げられる。
取材・文/夏目幸明 撮影/中村將一

