

















【短期集中連載】〈第4回〉PDFの文字を読み取ってExcelに変換するプログラム実例
『めんどうな作業が秒速で終わる! Excel×Python自動化の超基本』(宝島社)の著者である伊沢剛さんに、事務作業を劇的に時短化するExcel×Pythonのすごさを解説していただく本連載。
最終回となる第4回は、PDFファイルにある文字を読み取り、Excelに変換するプログラムを紹介! PDFファイルの内容を加工したいときにとても便利です。
PDFの文字もプログラムで読み取れる!
取引先などから送ってもらったPDFの内容を、自分のところで加工したい……「加工できるデータをください」と言いづらいときや急いでいるとき、どうすればいいものか困ってしまいますよね。
みなさん仕方なく、PDFを目視で手打ちしてWordやExcelに転記しているのではないでしょうか。
しかし、このようなやり方では非効率ですし、ミスが発生することは必至。ところがPythonを使えば、PDF内にある文字データを読み取ってExcelファイルに書き出すことが可能です。
今回は、次のような「旅行スケジュール.pdf」を読み取り対象にしてみましょう。当然、このままでは文字データを加工することはできません。

このPDFをフォルダに収納したデータで、以下のようなPythonプログラムを動かします。
PDFファイル内の表をExcelに取り込むプログラム
#2020/8/30 伊沢 剛
import pandas as pd
import camelot.io as camelot
#pdfファイルを読み込む
table = camelot.read_pdf(“旅行スケジュール.pdf”)
lists = [] #一時保存用リスト
for t in table:
lists.append(t.df)
df = pd.concat(lists) #データフレームを結合
# excelファイルへ出力
with pd.ExcelWriter(“outFile.xlsx”) as writer:
df.to_excel(writer, sheet_name=’sheet1′, index=False, header=False)
前回と同じくプログラムの細かい説明は避けますが、このプログラムでは「PDFファイルを読み込む」動作と「読み込んだデータをExcelファイルに書き出す」動作の、大きく2つの動作が行われています。
プログラムを実行すると、フォルダの中に次のように、「outFile.xlsx」というExcelファイルが作成されているはずです。
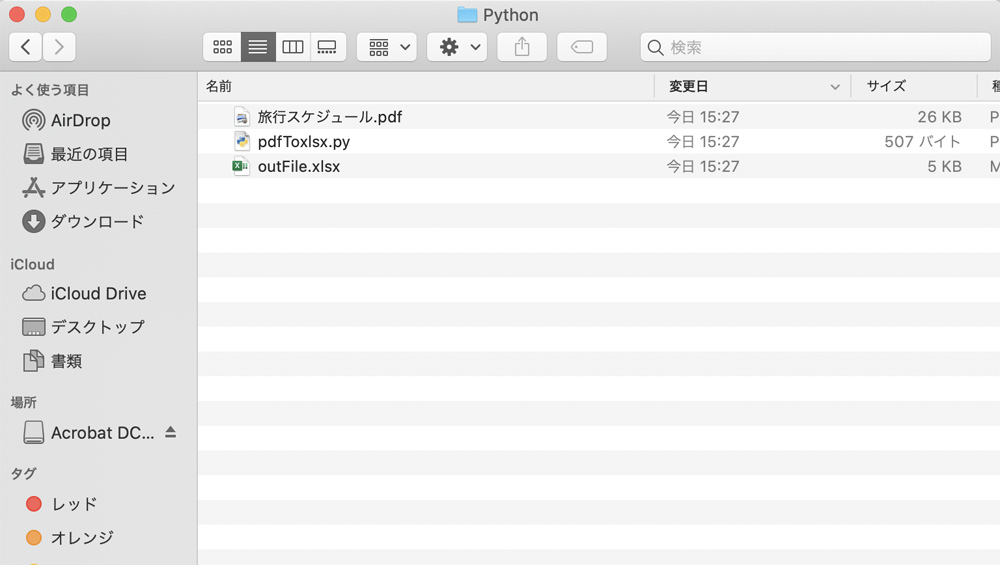
「pdfToxlsx.py」というファイルは、プログラム自体のデータ。Pythonのファイルはすべて「.py」という拡張子になるのが決まりごとです。
では、作成された「outFile.xlsx」をExcelで開いてみましょう。
次のようになっていれば、成功です。

「旅行スケジュール.pdf」の表に記載されていた文字が、すべてExcelに転記されていますね。
これで、わざわざ手で転記しなくても、PDFのデータを加工することができます。
実際のプログラムの動きは、次の動画で確認できます。
以上が、本連載でのExcel×Pythonの紹介です。
Pythonのすごさ、なんとなくおわかりいただけたでしょうか。
Pythonマスターでなくても、Pythonが「少しわかる」だけで、人生の可能性は大きく広がります。普段の仕事を自動化したり、自分の会社のエンジニアとPythonを用いる仕事の話をしたりできるようになる。それだけでも大きなアドバンテージです。
まずはできるところからプログラミングを少しだけかじって、人生に役立ててほしい。ハマったら、プロになるぐらい極めてもいい。それが、私のYou Tubeチャンネルと本連載による発信の源にある、共通のメッセージです。

『めんどうな作業が秒速で終わる! Excel×Python自動化の超基本』(宝島社)
著/伊沢剛(教育系YouTuber)
定価/1980円+税
電子書店
https://www.amazon.co.jp/dp/4299008154/ref=cm_sw_r_tw_dp_x_XQWFFb4NSKKGN

