


















REGEXEXTRACT関数の基本的な仕組みから使い方までを初心者向けに解説する記事である。数字やメールアドレスの抽出方法、よく使う正規表現の例、さらに「#N/A」などのエラー原因と対処法も分かりやすく紹介している。
目次
REGEXEXTRACT関数は、文字列の中から特定のパターンに一致する部分だけを抽出できる便利な関数である。しかし正規表現の書き方が分からず、使い方やエラーでつまずく人も少なくない。
本記事では、REGEXEXTRACT関数の基本的な仕組みから具体的な使い方、よくあるエラーの対処法までを画像付きで分かりやすく解説する。
REGEXEXTRACT関数とは

REGEXEXTRACT関数は、文字列の中から特定のパターンに一致する部分だけを抽出できる関数である。ここではREGEXEXTRACT関数の概要と利用シーンについて解説する。
■ REGEXEXTRACT関数でできること
REGEXEXTRACT関数では、正規表現というルールに基づいて、文字列の一部を抽出できる。例えば、次のような処理が可能である。
- 文章の中から数字だけを抽出する
- メールアドレスからドメイン部分のみを取り出す
- 「商品番号:A-1234」から1234のみを抜き出す
- URLの中から特定の文字列だけを取得する
このように規則性のある文字列を自動で取り出せるため、データ整理や一覧表の作成を効率化できる。
■ 主な利用シーン
REGEXEXTRACT関数は、データを整理・分析する場面で活用されることが多い。例えば次のようなシーンで役立つ。
- 顧客リストからメールアドレスのみを抽出する場合
- 住所データから郵便番号だけを取り出す場合
- 商品コードや管理番号の一部を分離したい場合
- 問い合わせ内容から特定の情報だけを抜き出したい場合
このように、文字列の中から必要な情報だけを抽出したい場面で非常に便利な関数である。
REGEXEXTRACT関数の使い方

ここではREGEXEXTRACT関数の基本的な使い方を解説する。
■ 基本構文と引数の意味
REGEXEXTRACT関数の基本構文は次の通りである。
=REGEXEXTRACT(文字列, 正規表現)
それぞれの引数の意味は以下の通りである。
文字列:抽出したいデータが入力されているセル
正規表現:どのようなパターンを抽出するかを指定するルール
例えば、A1セルに「商品番号:1234」と入力されている場合、数字だけを抽出したいときは正規表現に「数字」を表すパターンを指定する。
このように、「どこから」「どんなルールで」抽出するかを設定するのが基本である。
■ よく使う正規表現パターン
正規表現でよく使う基本パターンは次の通りである。
- \d :数字1文字
- \d+ :1文字以上の連続した数字
- [A-Za-z] :英字1文字
- . :任意の1文字
- + :直前の文字が1回以上繰り返される
- * :直前の文字が0回以上繰り返される
まずは数字抽出のような簡単な例から試すことが理解への近道である。
■ 数字を抽出する方法
例えば、「注文番号:5678」というデータから数字だけを取り出す手順は次のとおりである。
- セルに「注文番号:5678」と入力する
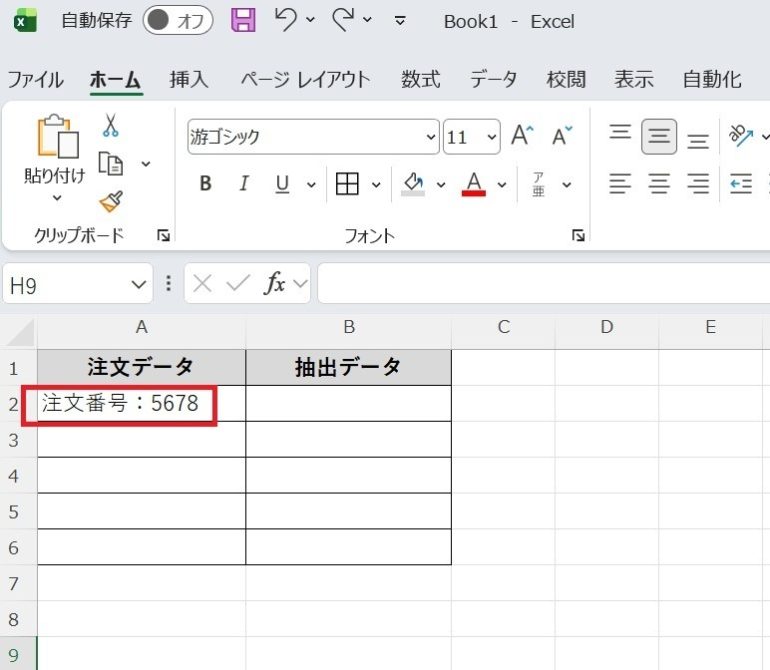
- 結果を表示させたいセルを選択する
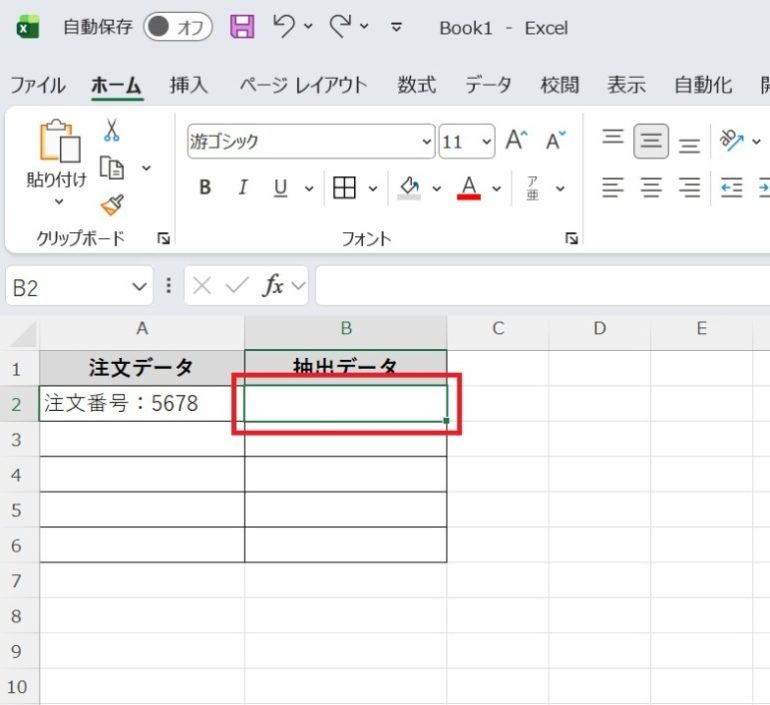
- そのセルに=REGEXEXTRACT(A2,”\d+”)を入力する
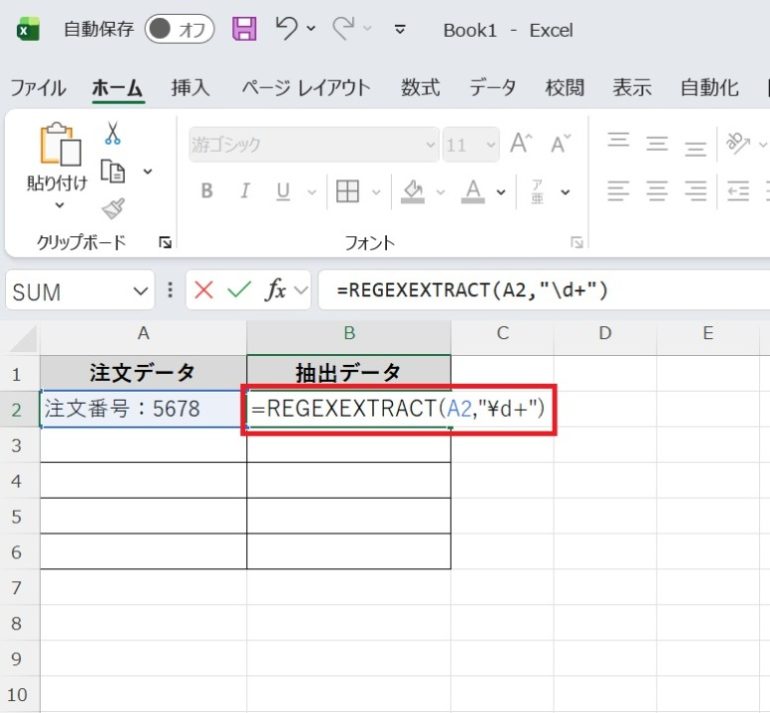
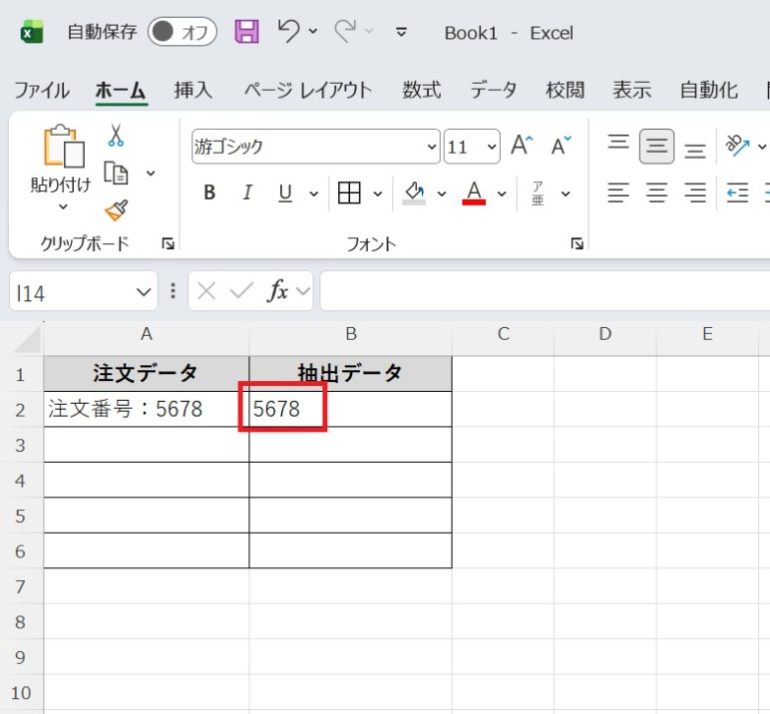
- Enterキーを押すと、B2セルに「5678」と表示される。
■ メールアドレスを抽出する方法
例えば、「連絡先:sample@example.com」という文字列からメールアドレスを抽出する手順は次の通りである。
- A2セルに「連絡先:sample@example.com」と入力する
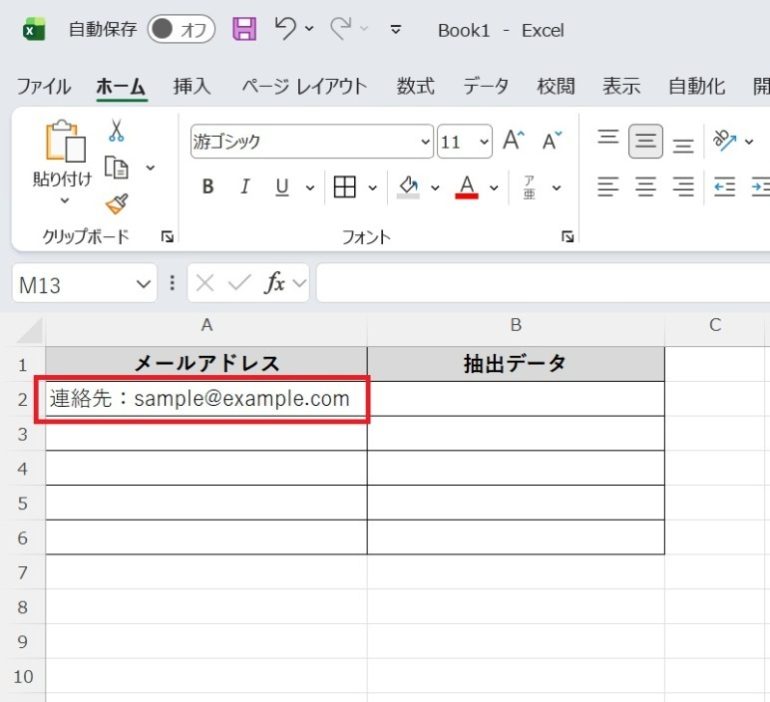
- 結果を表示させたいセルを選択する
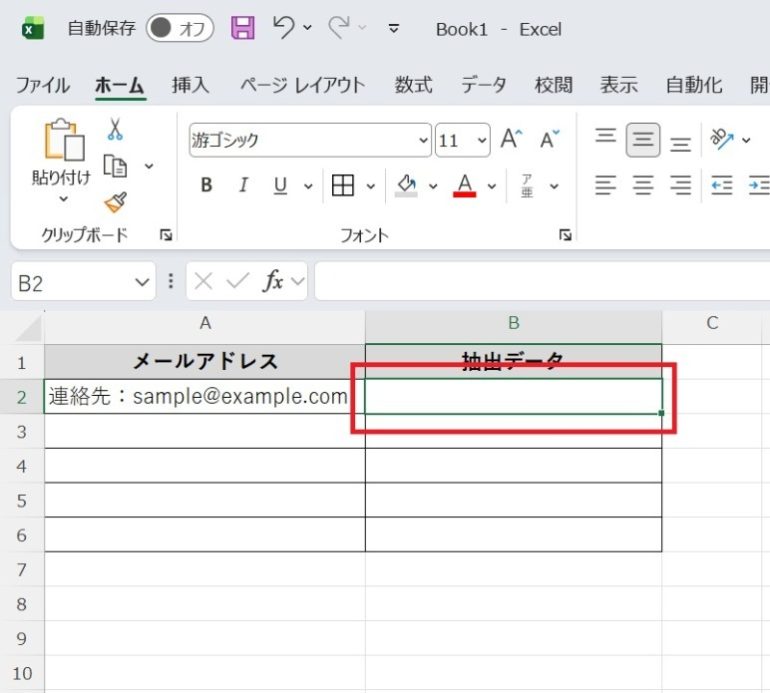
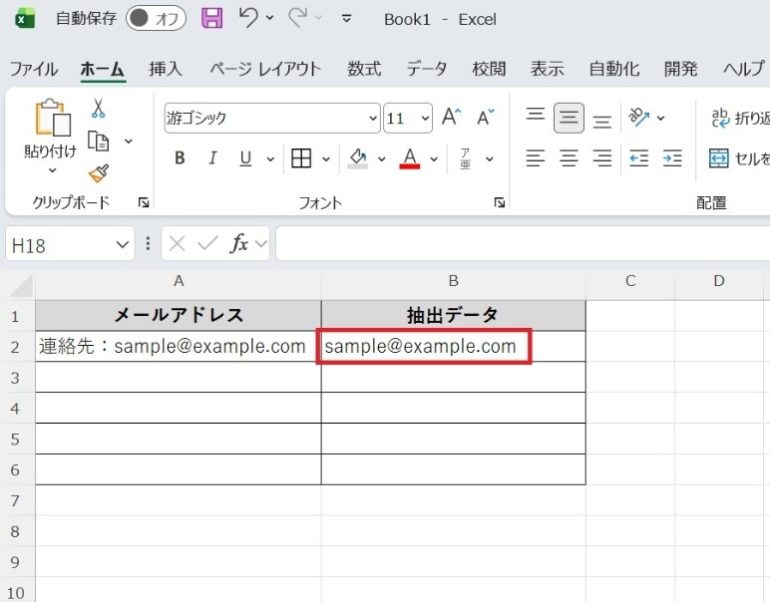
- B2セルに=REGEXEXTRACT(A2,”[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}”)を入力する
![B2セルに=REGEXEXTRACT(A2,"[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}")を入力した画面](https://dime.jp/wp-content/uploads/2026/02/image-126-770x455.jpeg)
- Enterキーを押すと、「sample@example.com」と表示される
REGEXEXTRACT関数のよくあるエラーと対処法

REGEXEXTRACT関数は便利な関数であるが、正規表現の指定方法によってはエラーが表示されることがある。ここでは、よくあるエラーとその対処法を解説する。
■ 「#N/A」エラーが表示される
「#N/A」エラーは、指定した正規表現に一致する文字列が見つからない場合に表示される。
主な原因
- 正規表現が対象データと一致していない
- 抽出したいデータがそもそも含まれていない
- 全角と半角が混在している
対処方法
- 抽出対象のセルに目的の文字列が含まれているか確認する
- 正規表現のパターンを簡単なもの(例:\d+)にして動作確認する
- 半角・全角の違いがないか見直す
一致しない場合は必ず「#N/A」が表示されるため、まずはパターンを疑うことが重要である。
■ 「一致が見つかりません」と表示される
「一致が見つかりません」と表示される場合も、基本的にはパターン不一致が原因である。
主な原因
- 正規表現が厳しすぎる
- 余計な記号やスペースが含まれている
- 抽出条件を細かく指定しすぎている
対処方法
- 正規表現を一度シンプルにする
- まずは部分一致から試す
- 抽出対象の文字列をコピーして正確に確認する
複雑な正規表現をいきなり使うのではなく、段階的に組み立てることが有効である。
■ 「#VALUE!」エラーが出る
「#VALUE!」エラーは、数式の書き方や引数の指定に問題がある場合に発生する。
主な原因
- ダブルクォーテーションの閉じ忘れ
- カンマの位置が誤っている
- セル参照が正しくない
対処方法
- ダブルクォーテーションが正しく閉じられているか確認する
- カンマの位置を確認する
- セル参照が正しいか見直す
数式の文法ミスがないかを確認することで解決する場合が多い。
■ 正規表現がうまく機能しない
エラーは出ないが、期待どおりに抽出できないケースもある。
主な原因
- 「.」が改行を含まない
- 「+」「*」の使い方を誤っている
- 特殊文字をそのまま使用している
対処方法
- 特殊文字を使う場合はエスケープする
- 正規表現を細かく分解して確認する
- 一部の文字列だけを対象にテストする
正規表現は記号の意味を正しく理解することが重要である。
■ 思った部分が抽出されない
意図しない部分が抽出されることもある。
主な原因
- 正規表現が広すぎる
- 最初に一致した部分だけが抽出される仕様を理解していない
- 複数候補がある場合の指定方法が不適切
対処方法
- 抽出範囲をより具体的に指定する
- 括弧を使って抽出対象を限定する
- 一度に複雑な処理をしようとしない
REGEXEXTRACT関数は「最初に一致した部分のみ」を返す仕様であるため、その特性を理解して使うことが重要である。
まとめ
この記事では、REGEXEXTRACT関数の基本的な仕組みから具体的な使い方、そしてよくあるエラーとその対処法までを解説した。
REGEXEXTRACT関数は、文字列の中から特定のパターンに一致する部分だけを抽出できる関数である。規則性のあるデータを扱う場面で特に効果を発揮し、作業の効率化につながる。
本記事の重要ポイントは次の通りである。
- REGEXEXTRACT関数は「=REGEXEXTRACT(文字列, 正規表現)」の形式で使用する
- 正規表現を使って、数字やメールアドレスなどを抽出できる
- 一致するデータがない場合は「#N/A」エラーが表示される
- 「#VALUE!」エラーは数式の入力ミスが原因であることが多い
- 最初に一致した部分のみが抽出される仕様である
特に重要なのは、正規表現を段階的に確認することである。いきなり複雑なパターンを設定するのではなく、簡単な式から動作確認を行い、少しずつ調整していくことが成功のポイントである。
REGEXEXTRACT関数を使いこなせるようになれば、文字列データの整理や分析を効率的に行えるようになる。まずは基本的な例から実践し、正規表現に慣れていくことが重要である。
構成/編集部

