
















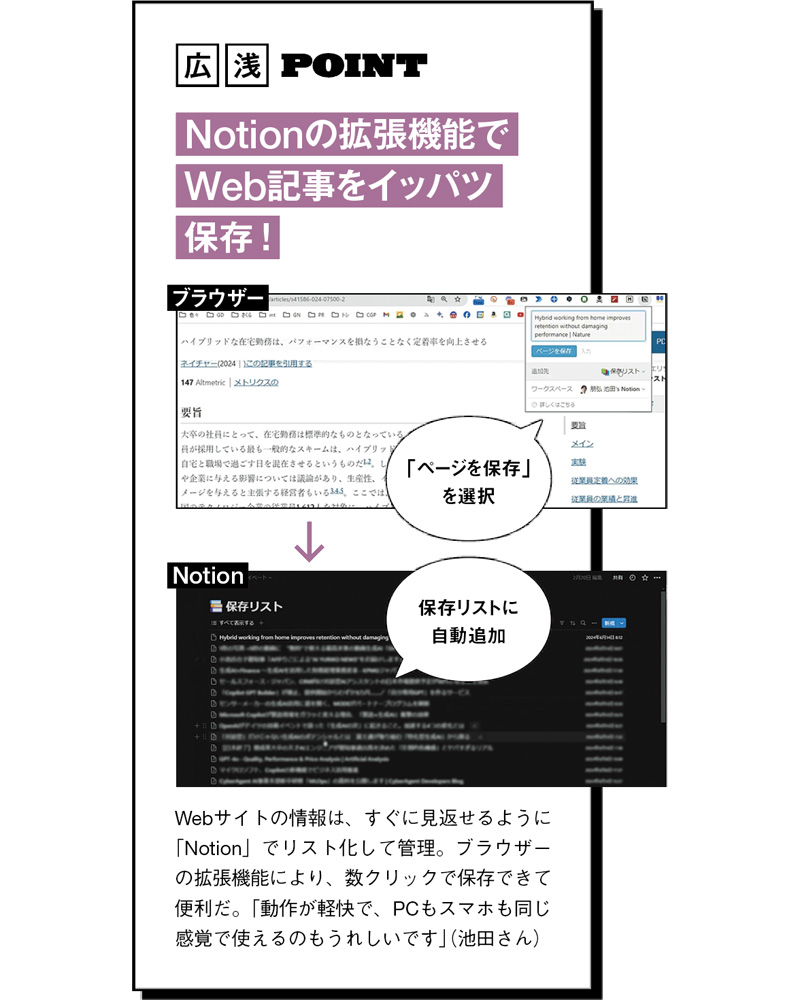
Web&PDF情報の高効率な収集&整理は3つのAIを組み合わせて使う
言語モデル「GPT-4o」の登場や『iPhone』の「ChatGPT」搭載予定など、話題が尽きないAI。情報収集への生かし方を専門家の池田朋弘さんに聞いた。
 Workstyle Evolution
Workstyle Evolution
池田朋弘さん
生成AIのビジネス導入支援や研修などを行なう。著書の『ChatGPT最強の仕事術』は1か月で2万部を突破。
AIを情報収集に生かすには個々の特徴を把握するところから
いまやAIはWebブラウザーやスマホに組み込まれるのが当たり前になった。多様化も進んでおり、個々のAIには得意・不得意があると池田さん。情報収集で活用する際は各特徴を把握し、使い分けることが必要だという。
「AIは生成系、検索系、読込系の3つに大別できます。生成系AIの代表的なサービスは『ChatGPT』。ユーザーが渡した情報を解析・整理し、そこから新しいアイデアを考えるのが得意です。一方、検索系AIで評価が高いのは『Perplexity(パープレキシティ)』。グーグル検索と同様に、ネット上にある既存の文章を組み合わせて、要約などをしてくれます。読込系AIとしては、グーグルの『NotebookLM』が挙げられます。PDFファイルなど、特定の情報を読み込ませて、深堀りしていくのに有用です」(池田さん)
これらAIは組み合わせて使うとさらに効率的に。池田さんのアドバイスなどを参考に情報収集に活用しよう。
生成系AI「ChatGPT」
 「ChatGPT」などの生成AIは既存データの分析・整理や論点設定が得意。一方、情報収集が不得手で、正確性は保証できない。画像上の文字などを認識・分析させる場合には「ChatGPT」よりも「Gemini」のほうが精度は高い。
「ChatGPT」などの生成AIは既存データの分析・整理や論点設定が得意。一方、情報収集が不得手で、正確性は保証できない。画像上の文字などを認識・分析させる場合には「ChatGPT」よりも「Gemini」のほうが精度は高い。
検索系AI「Perplexity」
 特定の語句や事象について調べる際には「Perplexity」を使いたい。膨大なネット上の情報を検索したうえで、複数の引用元から得られた情報を要約してくれる。Google検索よりも効率良く情報を収集でき、生成AI系よりも正確だ。
特定の語句や事象について調べる際には「Perplexity」を使いたい。膨大なネット上の情報を検索したうえで、複数の引用元から得られた情報を要約してくれる。Google検索よりも効率良く情報を収集でき、生成AI系よりも正確だ。
読込系AI「NotebookLM」
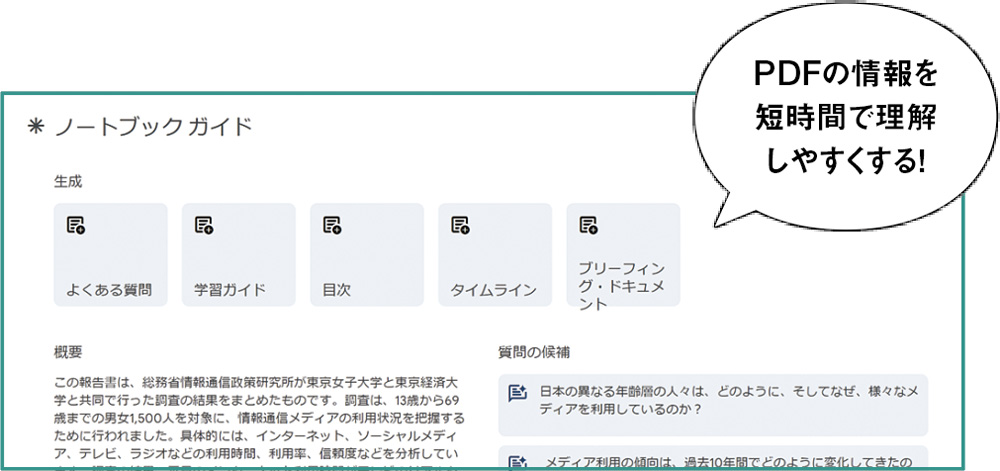 Web検索などから得られた情報を深堀りするのに向くのが「NotebookLM」。特定のPDFやテキストファイルなどを読み込み、その内容に基づいて議論したり、理解を深めたりするのに役立つ。複数資料の情報を横断して整理もできる。
Web検索などから得られた情報を深堀りするのに向くのが「NotebookLM」。特定のPDFやテキストファイルなどを読み込み、その内容に基づいて議論したり、理解を深めたりするのに役立つ。複数資料の情報を横断して整理もできる。

