
















微妙な結果に終わった文字起こし、日本語処理は苦手か
一方で、速度が完全に同じかというとそうでもない。特に処理能力を必要とする、文字起こしのような機能では、完了までに差が出る印象だ。録音の時間が長くなってくると、その差は顕著になる。とは言え、Galaxy AIのボイスレコーダーの文字起こしは、リアルタイムではなく、録音後にまとめて処理をかける形のもの。時間がよりかかるのは確かだが、不便とまでは言えない。
 リアルタイムで文字起こしをするPixelとは異なり、録音後にまとめて処理をかける仕組み
リアルタイムで文字起こしをするPixelとは異なり、録音後にまとめて処理をかける仕組み
その文字起こしだが、日本語の精度にはまだかなり不満がある。例えば、以下は会議室で開催された記者会見を録音し、テキスト化したものの一部だ。ご覧になっていただければ一目瞭然だが、テキストを読むだけだと、何を言っているのかがさっぱりわからない。固有名詞はもちろんのこと、一般名詞も割と適当な文字が割り当てられており、さらに句点の場所も不正確だ。
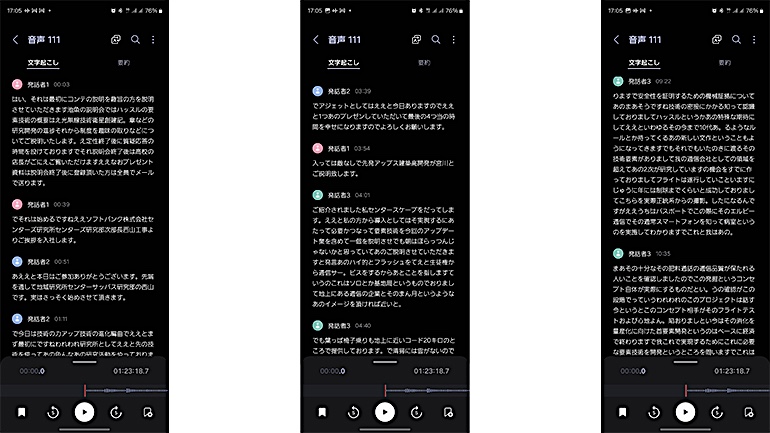 ソフトバンクがHAPSの技術を説明する記者会見で録音した音声をテキスト化してみた……が、これだけだと、何を言っているのかがさっぱりわからない
ソフトバンクがHAPSの技術を説明する記者会見で録音した音声をテキスト化してみた……が、これだけだと、何を言っているのかがさっぱりわからない
同じ文字起こし機能を備えたボイスレコーダーを搭載した端末として有名なのはPixelシリーズだが、こちらと比べてみると、精度の違いがわかりやすい。以下はPixel 8で録音しながらテキスト化した画面。こちらも、固有名詞などは完ぺきとは言いがたいものの、何を話しているかの概要はおおまかにつかむことが可能だ。
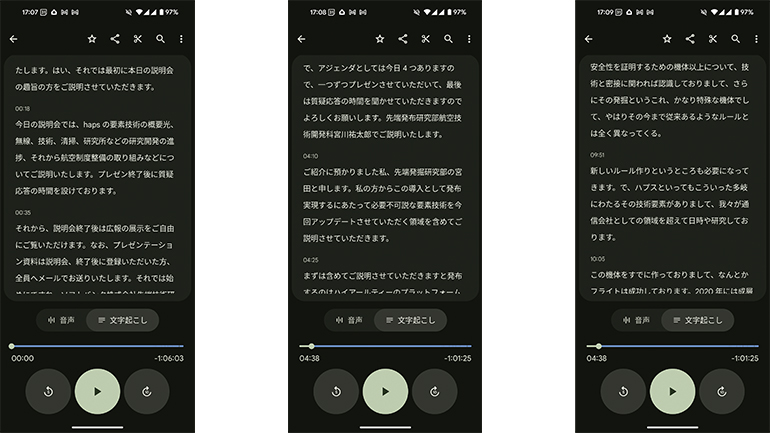 同じ部分をPixelでテキスト化したものと比べてみると、違いは歴然。こちらも間違いはあるが、話していることは何となく伝わるレベルだ
同じ部分をPixelでテキスト化したものと比べてみると、違いは歴然。こちらも間違いはあるが、話していることは何となく伝わるレベルだ
しかも、Pixelのボイスレコーダーはリアルタイムでテキスト化されるため、その場でサッと内容を振り返るようなシーンでも活用できる。条件的には、リアルタイムで処理をかける方が厳しいようにも思えるが、精度では大きな差が出てしまった。おそらくだが、音声認識の部分で、Galaxy AIは環境の影響を受けやすいのかもしれない。
反響や音量などの影響を最小限にするため、動画配信されている記者会見を直接USB-Cで録音したものをテキスト化してみたが、こちらに関しては、まずまずの精度が出ている。流れるようにしゃべるよりも、ある程度原稿を読み上げるように、1語1語、正確にはっきり発音した方が、正確な文字として認識されやすいようだ。
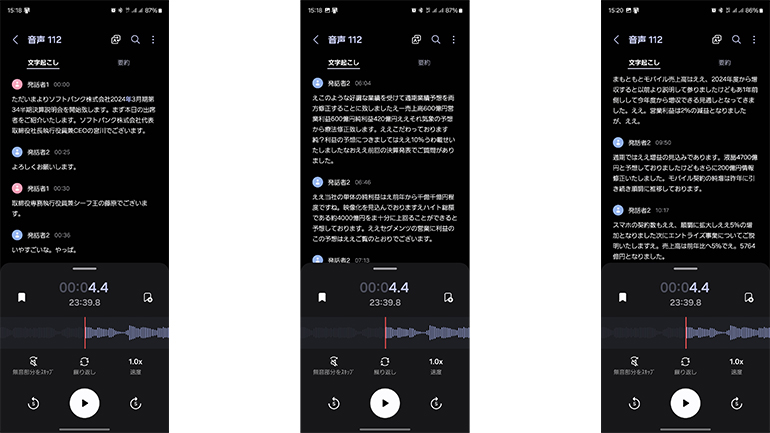 配信されている動画の音声を直接USB-C経由で録音したところ、精度が上がった。環境の影響を受けやすいことがうかがえる
配信されている動画の音声を直接USB-C経由で録音したところ、精度が上がった。環境の影響を受けやすいことがうかがえる
また、英語での認識率は比較的高く、精度の低さは日本語特有の問題であることがわかる。以前から日本語に対応しており、実績を積み重ねているPixelとの比較は酷かもしれないが、この部分は、改善の余地がまだまだある。日本語認識のモデル改善など、ソフトウエアップデートで対応できることが多いだけに、サムスン電子のがんばりには期待したいところだ。
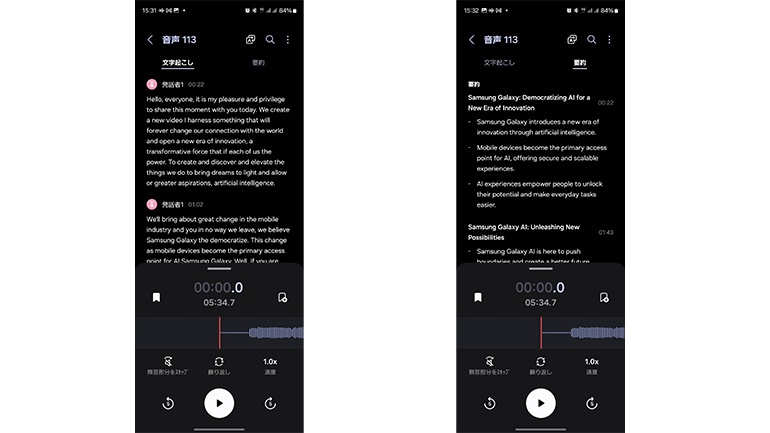 英語で配信されたイベントを文字にしたもの。結果はなかなか優秀だ。元のデータがしっかりしていると、要約機能を使った時の精度も上がる
英語で配信されたイベントを文字にしたもの。結果はなかなか優秀だ。元のデータがしっかりしていると、要約機能を使った時の精度も上がる

