


















OpenAIは2026年3月5日、ChatGPT(GPT-5.4 Thinkingとして)、API、そしてCodexでGPT-5.4をリリースした。これはプロフェッショナルな業務において最も有能、かつ効率的なフロンティアモデルとなる。
また複雑なタスクで最高のパフォーマンスを求めるユーザーのために、ChatGPTとAPIでGPT-5.4 Proを同時リリースする。
タスクとの関連性を保ちながら、迅速に高品質な回答が得られる
ChatGPTでは、GPT-5.4 Thinkingが思考の事前計画を提供できるようになったため、処理中に途中でコースを調整し、追加のターンなしで、より必要な情報に近い最終出力を得ることができる。
GPT-5.4 Thinkingは、特に非常に具体的なクエリにおけるディープウェブリサーチの改善に加え、より長い思考時間を必要とする質問のコンテキストをより適切に維持する。
これらの改善により、迅速に、そしてタスクとの関連性を保ちながら、高品質な回答が得られるようになった。
■ネイティブで最先端のコンピューター利用機能を備えた最初の汎用モデル
CodexとAPIにおいて、GPT-5.4はネイティブで最先端のコンピューター利用機能を備えた最初の汎用モデルであり、エージェントがコンピューターを操作し、アプリケーション間で複雑なワークフローを実行できるようにする。
そして最大100万トークンのコンテキストをサポートして、エージェントが長期にわたってタスクを計画、実行、検証できるようにする。
GPT-5.4は、ツール検索機能により、ツールとコネクタの大規模なエコシステム全体でモデルが機能する方法も改善し、エージェントがインテリジェンスを犠牲にすることなく適切なツールをより効率的に見つけて使用できるようにする。
最後に、GPT-5.4はこれまでで最もトークン効率の高い推論モデルであり、GPT-5.2と比較して問題を解決するために使用するトークンが大幅に少なく、トークンの使用量を削減することで、速度を向上している。
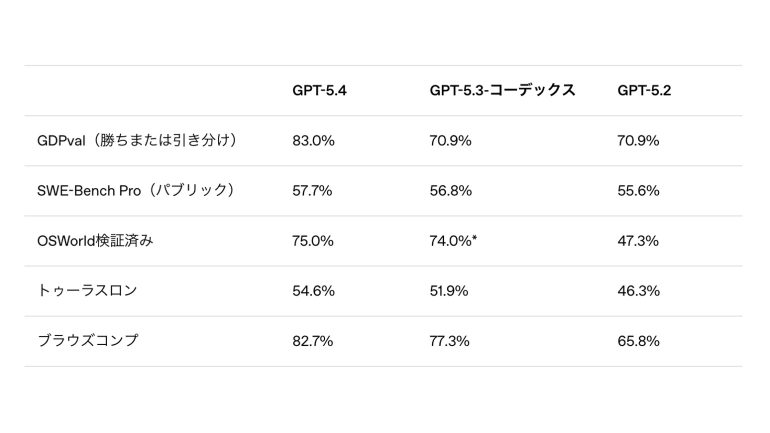
※ 以前は64.7%と報告されていた。GPT-5.3-Codexは、元の画像解像度を維持する新しく導入されたAPIパラメータにより74.0%を達成した。
知識労働
GPT-5.2 の一般的な推論機能を基にして、GPT-5.4 は、専門家にとって重要な現実世界のタスクで、さらに一貫性のある洗練された結果を提供する。
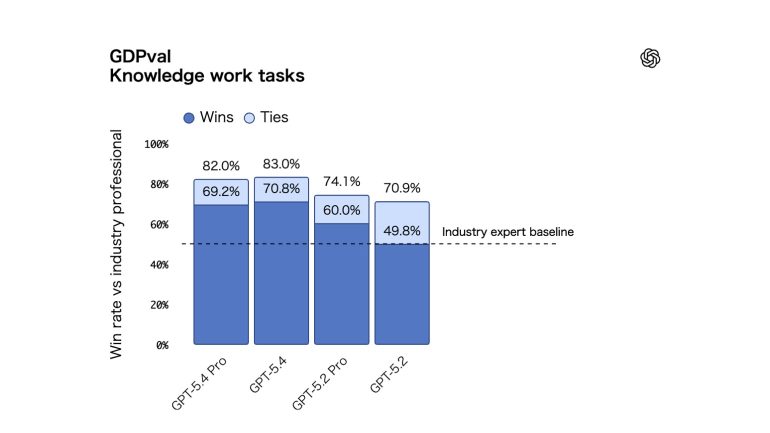
44の職業にわたって明確に指定された知識労働を生み出すエージェントの能力をテストするGDPval において、GPT‑5.4は新たな最高水準を達成。比較の83.0%で業界の専門家と同等かそれ以上を達した。一方、GPT‑5.2では70.9%だった。
<GDPval 知識労働タスク>
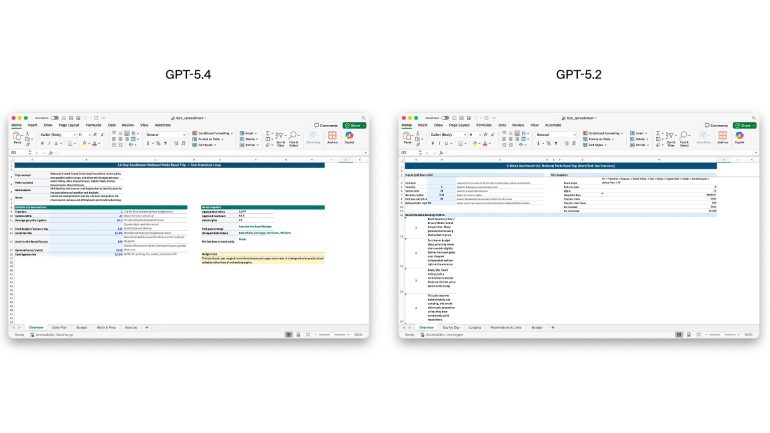
今回GPT-5.4のスプレッドシート、プレゼンテーション、ドキュメントの作成と編集能力の向上に特に重点が置かれた。
実際、投資銀行のジュニアアナリストが行なう可能性のあるスプレッドシートモデリングタスクの社内ベンチマークでは、GPT-5.4は平均87.3%のスコアを達成したが、GPT-5.2は68.4%だった。
プレゼンテーション評価プロンプトのセットにおいて、人間の評価者は、より美しい外観、より多様な視覚的要素、そしてより効果的な画像生成の使用により、GPT-5.4のプレゼンテーションをGPT-5.2よりも68.0%の割合で高く評価したという。
■コンピュータの使用と視力
GPT-5.4は、ネイティブなコンピュータ利用機能を備えた初の汎用モデルであり、これは開発者とエージェント双方にとって大きな前進となる。ウェブサイトやソフトウェアシステム全体で実際のタスクを実行するエージェントを構築する開発者にとって、現在利用可能な最高のモデルと言えるだろう。
このモデルの性能と柔軟性は、様々な設定でのコンピュータ使用をテストするベンチマークにも反映されている。
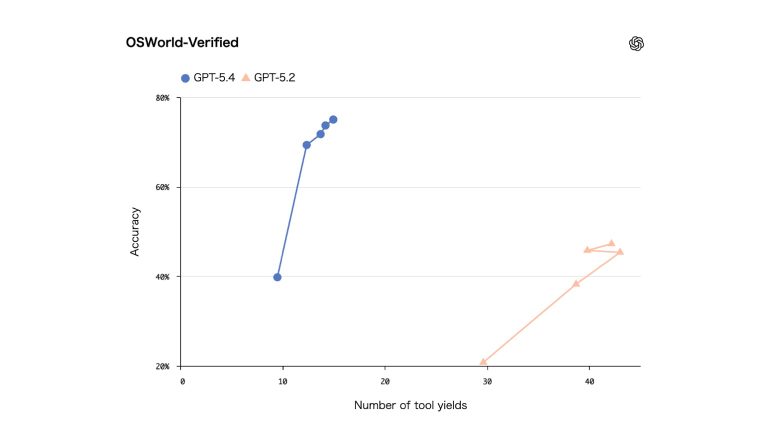
スクリーンショットとキーボード/マウス操作を通してデスクトップ環境をナビゲートするモデルの能力を測定するOSWorld-Verifiedにおいて、GPT-5.4は最高水準の75.0%の成功率を達成。GPT-5.2の47.3%を大きく上回っただけでなく、人間のパフォーマンスである72.4%も上回った。
ブラウザの使用をテストするWebArena-Verifiedでは、GPT-5.4はDOMとスクリーンショット駆動型インタラクションの両方を使用した場合に、GPT-5.2の65.4%と比較して67.3%という優れた成功率を達成している。
また、ブラウザの使用をテストするOnline-Mind2Webでは、GPT-5.4はスクリーンショットベースの観察のみを使用して92.8%の成功率を達成。70.9%の成功率を達成したChatGPT Atlasのエージェントモードを上回っている。
<OSWorld検証済み>
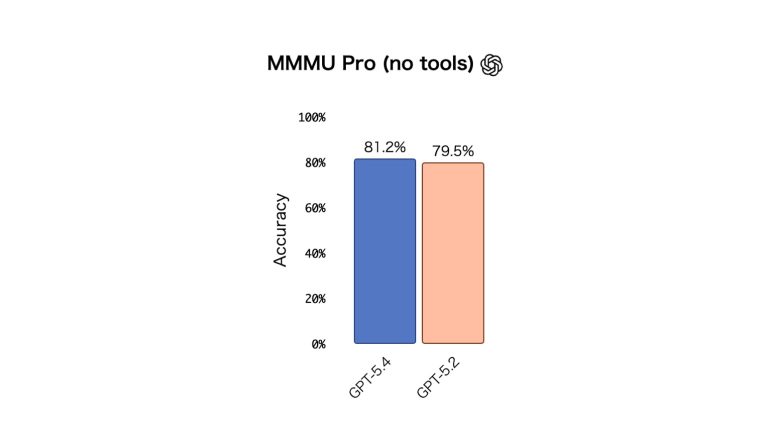
そしてモデルの視覚的理解と推論をテストするMMMU-Proにおいては、GPT-5.4はツールを使用せずに81.2%の成功率を達成。GPT-5.2の79.5%から向上した。
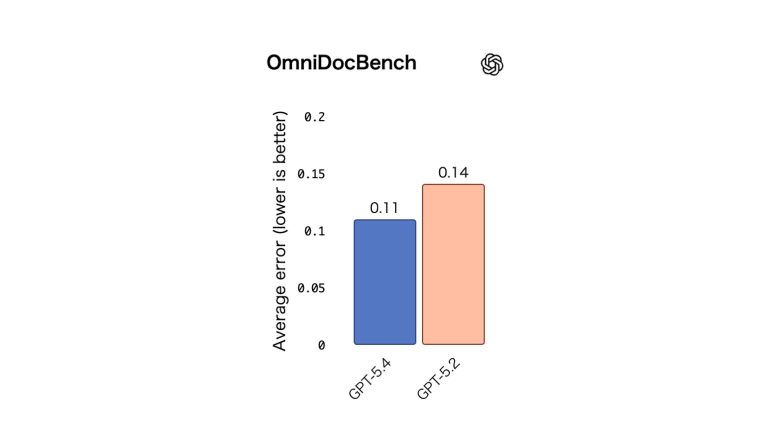
視覚認識の向上は、ドキュメント解析機能の向上にもつながる。OmniDocBenchでは、推論努力なしのGPT-5.4は平均誤差(モデル予測とグラウンドトゥルース間の正規化編集距離で測定)0.109を達成しており、GPT-5.2の0.140から改善した。
<MMMU Pro(ツールなし)>
<オムニドックベンチ>
■コーディング
GPT-5.4は、GPT-5.3-Codexのコーディングの強みと、最先端の知識作業およびコンピューター利用能力を兼ね備えている。これらの能力は、モデルがツールを活用し、反復処理を行い、手動介入を少なくして作業を進めることができる、長時間実行タスクにおいて特に重要だ。
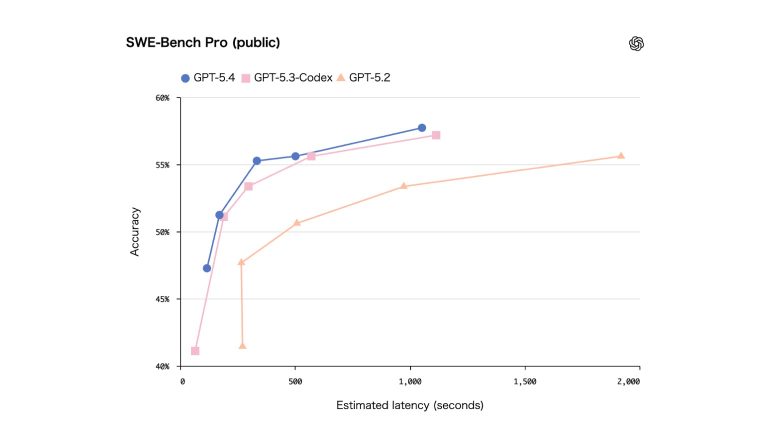
SWE-Bench Proにおいて、GPT-5.3-Codexと同等またはそれ以上の性能を発揮しながら、推論処理全体のレイテンシを低く抑えている。
またCodexの/fastモードをオンにすると、GPT-5.4でトークン速度が最大1.5倍高速になる。
<SWE-Bench Pro(公開)>
ツール検索
APIでは、GPT‑5.4でツール検索が導入された。これにより、多くのツールが与えられた場合でもモデルが効率的に動作できるようになる。
以前は、モデルにツールが与えられると、すべてのツール定義がプロンプトに事前に含まれていた。多くのツールを持つシステムでは、これによりリクエストごとに数千、あるいは数万ものトークンが追加され、コストが増加。さらに応答が遅くなり、モデルが決して使用しない可能性のある情報でコンテキストが混雑する可能性があった。
ツール検索では、GPT-5.4はツール検索機能に加えて、利用可能なツールの軽量リストを受け取る。モデルがツールを使用する必要があるときは、そのツールの定義を検索して、その時点で会話に追加することができる。
そんな効率性の向上を実証するために、ScaleのMCP Atlasから250のタスクを評価した。
36台のMCPサーバーすべてを2つのモードで有効化したベンチマーク。
(1) すべてのMCP関数をモデルコンテキストで直接公開するモードと、
(2) すべてのMCPサーバーをツール検索の背後に配置するモードだ。
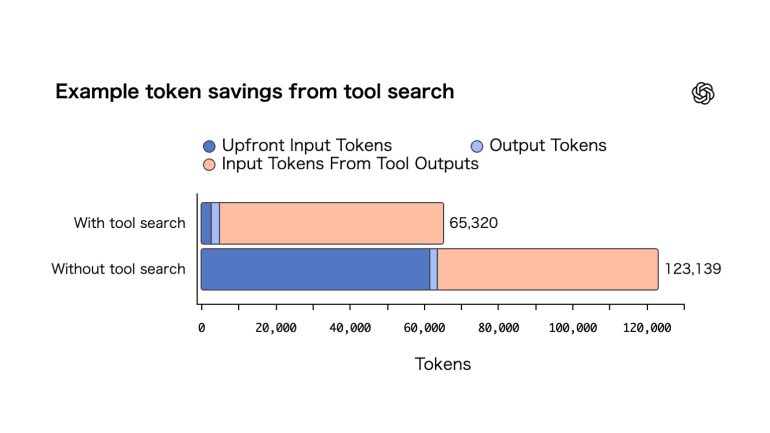
ツール検索構成では、同じ精度を維持しながら、トークン使用量を47%削減した。
<ツール検索によるトークン節約の例>
■エージェントツール呼び出し
GPT-5.4はツール呼び出しも改善され、推論中にツールをいつどのように使用するかを決定する際の精度と効率性を向上させている。特にAPIにおいて、それは顕著だ。
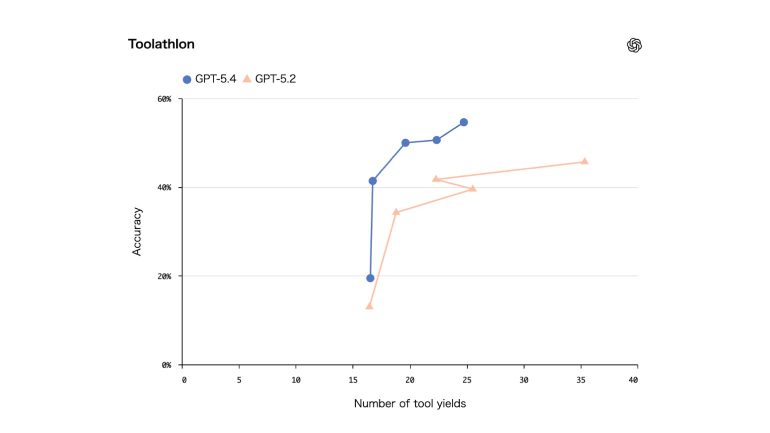
GPT-5.2との比較で、AIエージェントが現実世界のツールとAPIをどれだけ効果的に活用して、複数ステップのタスクを完了できるかをテストするベンチマーク「Toolathlon」において、より少ないターン数でより高い精度を達成している。
例えば、エージェントはメールを読み、課題の添付ファイルを抽出してアップロードし、採点し、結果をスプレッドシートに記録する必要がある。
<トゥーラスロン>
■ウェブ検索の改善
GPT-5.4は、エージェントによるWeb検索においても、より優れた能力を発揮する。
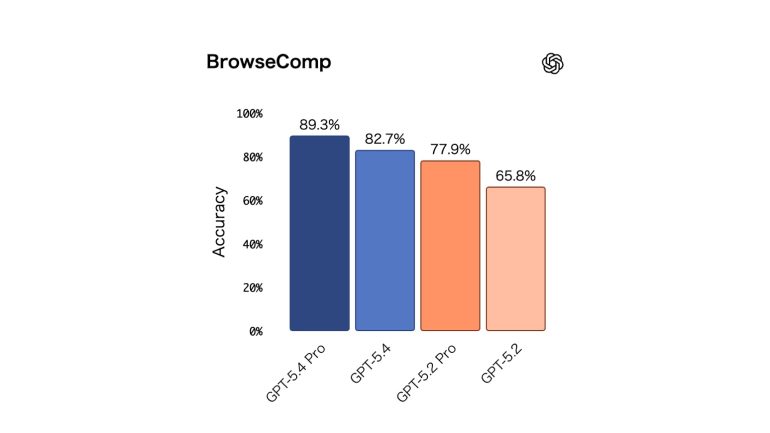
AIエージェントがWebを継続的に閲覧し、見つけにくい情報を見つける能力を測るBrowseCompにおいて、GPT-5.4はGPT-5.2を17%(絶対値)上回り、GPT-5.4 Proは89.3%という新たな最高記録を達成した。
実際には、これはGPT-5.4思考が、Web上の多数の情報源から情報を収集する必要がある質問に答える能力に優れていることを意味している。
特に「干し草の山から針を探す」ような質問に対して、GPT-5.4思考は、複数のラウンドにわたってより粘り強く検索を行ない、最も関連性の高い情報源を特定し、それらを統合して明確で論理的な回答を導き出すことができる。
<ブラウズコンプ>
在庫状況と価格
GPT-5.4は、ChatGPTとCodex全体で、2026年3月5日より段階的に展開される。
ChatGPTでは、ChatGPT Plus、Team、Proのユーザーは、GPT-5.4 Thinkingを3月5日より利用可能になっている。
GPT-5.2 Thinkingは、有料ユーザー向けには、レガシーモデルセクションのモデルピッカーで3か月間利用できる。その後、2026年6月5日に廃止される。
EnterpriseプランおよびEduプランのユーザーは、管理者設定から早期アクセスを有効にすることができる。GPT-5.4 Proは、ProプランおよびEnterpriseプランで利用可能だ。GPT-5.4 思考の ChatGPT は GPT-5.2 思考から変更されていない。
CodexのGPT-5.4には、1MBのコンテキストウィンドウの試験的なサポートが含まれている。標準の272KBのコンテキストウィンドウを超えるリクエストは、通常の2倍のレートで使用制限にカウントされる。
APIでは、GPT-5.4は機能向上を反映してGPT-5.2よりもトークンあたりの価格が高くなっている。その一方で、トークン効率の向上により、多くのタスクに必要なトークンの総数を削減できる。バッチ処理とフレックス処理の価格は標準API料金の半額で、優先処理は標準API料金の2倍で利用が可能だ。

関連情報
https://openai.com/index/introducing-gpt-5-4/
構成/清水眞希


