

















OpenAI は2025年12月12日(米国時間)、専門的な業務や長時間稼働するエージェントを対象とした、最先端のフロンティアモデル「GPT‑5.2」を発表。
同日よりChatGPT ではInstant、Thinking、Proを有料プラン(Plus、Pro、Go、Business、Enterprise)から順次提供が開始された。
API プラットフォームでは、すべての開発者が同日からGPT‑5.2 ThinkingをResponses APIおよびChat Completions API でgpt-5.2 として利用できる。また、GPT‑5.2 Instant は gpt-5.2-chat-latest として、GPT‑5.2 Pro は Responses API で gpt-5.2-pro として提供される。
価格は入力トークン100万あたり1.75ドル、出力トークン100万あたり14ドルで、キャッシュされた入力には90%の割引が適用される。
本稿では、そんな「GPT‑5.2」の主な機能と特徴を、同社発表ブログから引用してお伝えする。
なおChatGPT では、GPT‑5.1をレガシーモデルとして有料ユーザー向けに3か月間提供した後、提供を終了する。
実務においてエキスパートレベルのパフォーマンスに到達
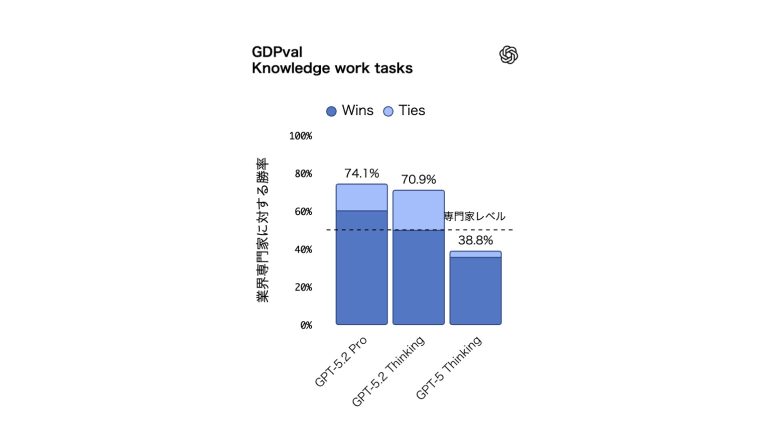
GPT‑5.2 Thinking は、実際の専門業務に最適な、これまでで最も優れたモデルだ。実際、44の職種にまたがる明確に定義された知識業務タスクを評価するベンチマーク GDPval において、GPT‑5.2 Thinking は新たな最高スコアを達成。同社のモデルとして初めて人間の専門家レベルに達した。
具体的には、GPT‑5.2 Thinking は難度の高い知識業務タスクの70.7%において、業界トップクラスの専門家と同等以上の結果を示した。これらのタスクには、プレゼンテーションやスプレッドシート、その他の成果物の作成などが含まれている。
GPT‑5.2 Thinking は、GDPval のタスクを業界専門家の11倍以上の速度、1%未満のコストで生成しており、人による確認と組み合わせることで専門業務を支援できることを示唆している。
※なお速度とコストの推計は過去の測定値に基づくものであり、ChatGPT 上での速度は状況により異なる場合がある。
■GPT‑5.2 Thinking のタスク平均スコアはGPT‑5.1 より9.3%高い結果に
さらに、Fortune 500企業向けに適切な書式と引用を含む3つの財務諸表モデルを作成したり、非公開化を前提としたレバレッジド・バイアウトモデルを構築したりするなど、投資銀行アナリスト初級レベルのスプレッドシートモデリングタスクを評価する同社の内部ベンチマークでは、GPT‑5.2 Thinking のタスク平均スコアは、59.1%から68.4%へと上昇。GPT‑5.1 より9.3%高い結果となった。
※ChatGPT で新しいスプレッドシートおよびプレゼンテーション作成機能を利用するには、有料プランに加入し、GPT‑5.2 Thinking か Pro を選択する必要がある。複雑な生成には数分かかることがある。
さらにGPT‑5.2 Thinking は、実世界のソフトウェアエンジニアリングを厳密に評価する SWE-Bench Pro において、55.6%という新たな最高スコアを達成した。
Python のみを評価対象とする SWE-bench Verified と異なり、SWE-Bench Pro は4言語を対象としており、汚染耐性の高さ、難易度、多様性、産業的関連性を重視した評価となっている。
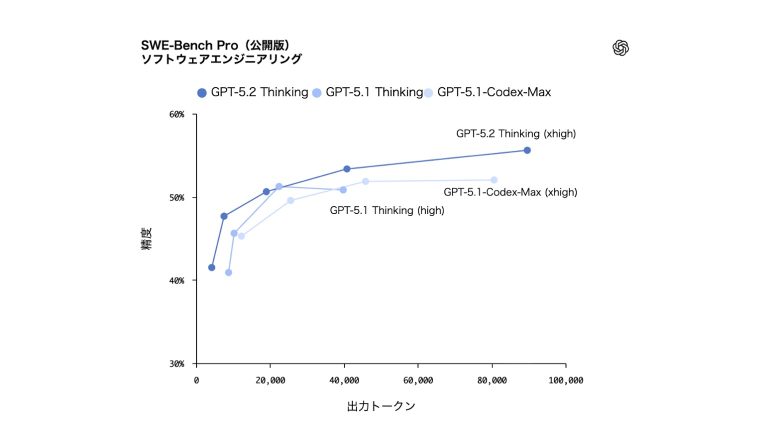
※SWE-bench Pro(新しいウィンドウで開く) では、モデルにコードリポジトリが与えられ、現実的なソフトウェアエンジニアリングタスクを解決するためのパッチを生成する必要がある。

■4-needle MRCR バリアントで、ほぼ100%の精度を達成した初めてのモデル
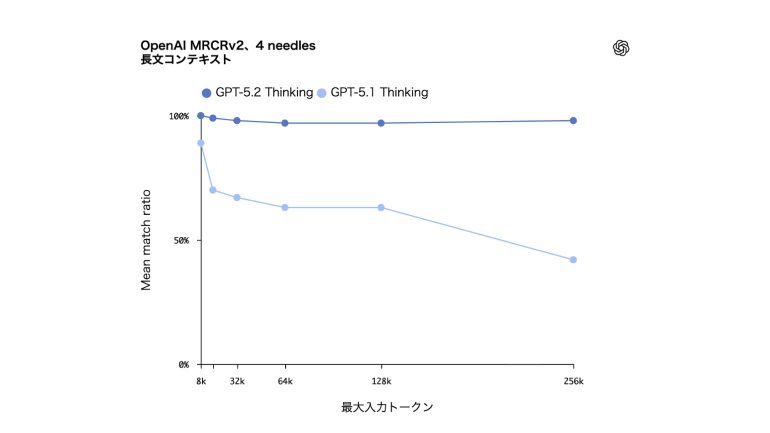
GPT‑5.2 Thinking は、長文コンテキスト推論においても新たな水準を達成。長い文書に分散した情報を統合する能力を評価する OpenAI MRCRv2 でトップレベルの性能を示した。
数十万トークン規模の関連情報を扱う高度な文書分析など、実世界のタスクにおいても、GPT‑5.2 Thinking は GPT‑5.1 Thinking より大幅に高い精度を発揮する。
特に、256k トークンまで扱える 4-needle MRCR バリアントで、ほぼ100%の精度を達成した初めてのモデルとなった。
実務面では、GPT‑5.2 を使ってレポートや契約書、研究論文、書き起こし、多ファイルのプロジェクトなどの長文ドキュメントを扱い、数十万トークン規模でも一貫性と精度を保ちながら作業できる。そのため、GPT‑5.2 は深い分析、情報統合、複数の情報源を扱う複雑なワークフローに特に適している。
このようにGPT-5.2 Thinking はGPT-5.1 (会話の温かさ) に続き、業務用途の「品質・一貫性・信頼性」に最適化。スプレッドシート / プレゼン資料作成 / コード生成 / 画像 / 長文理解 / ツール利用 / 複数ステップ実行が大幅に改善された。
ChatGPTでの仕事・学習体験の大幅な向上
GPT-5.2ファミリーは、仕事と学習の両面で実用性が大きく向上している。より使いやすく、応答が整理されて信頼性も高まり、対話も引き続き楽しめることを実感できるはずだ。
■GPT‑5.2 Instant
日常の仕事や学習に役立つ高速で頼れるモデルであり、情報探索、手順説明、技術文書作成、翻訳といった領域で明確な改善を示している。GPT‑5.1 Instant で導入された温かみのある対話トーンもそのまま継承した。初期テスターからは、重要な情報を先に示す、よりわかりやすい説明が特に高く評価されている。
■GPT‑5.2 Thinking
より深い業務に向けて設計されており、複雑なタスクをより洗練された形でこなせるよう支援していく。特に、コーディングや長文ドキュメントの要約、アップロードしたファイルに関する質問への回答、数学やロジックの段階的な説明、計画や意思決定を分かりやすい構造と、ていねいな説明で支援する能力が向上している。
■GPT‑5.2 Pro
高品質な回答が求められる難しい質問に適した、同社で最も高度かつ信頼性の高いモデルだ。初期テストでは、重大なエラーの減少や、プログラミングなどの複雑な領域における性能向上が確認されている。
セーフティ機能の継続的な強化
GPT‑5.2 は、GPT‑5 で導入した安全な回答生成に関する研究をさらに発展させ、安全性を保ちつつ最も有用な回答を返せるように訓練されたモデルででもある。
今回のリリースでは、センシティブな会話におけるモデルの応答を強化する取り組みを継続しており、自殺や自傷の兆候、メンタルヘルスの困難、モデルへの感情的な依存を示すプロンプトへの応答において大きな改善が見られている。
こうした重点的な改善により、同社ではGPT‑5.2 Instant と GPT‑5.2 Thinking の両モデルにおいて、GPT‑5.1 および GPT‑5 Instant / Thinking と比べて望ましくない応答がさらに少なくなっている、と説明している。
18歳未満のユーザーに対してセンシティブなコンテンツへのアクセスを制限できるよう、自動的に保護措置を適用する年齢推定モデルの段階的な導入が開始されている。
これは、18歳未満と判定できるユーザー向けに既に実施している保護措置や、ペアレンタルコントロールの仕組みをさらに強化したものだ。
関連情報
https://openai.com/ja-JP/index/introducing-gpt-5-2/
構成/清水眞希


