
















少量音声データから個人の音声を合成するZero/Few-shot音声合成技術も開発
 NTTはIOWN構想(※1)の柱の1つであるデジタルツインコンピューティング(以下、DTC)(※2)において、物理世界の制約を超えた活動や交流を通した機会増大や自己成長の実現を目指し、本人のように行動し本人と経験を共有する分身のようなAIエージェント「Another Me」の研究開発を進めている。
NTTはIOWN構想(※1)の柱の1つであるデジタルツインコンピューティング(以下、DTC)(※2)において、物理世界の制約を超えた活動や交流を通した機会増大や自己成長の実現を目指し、本人のように行動し本人と経験を共有する分身のようなAIエージェント「Another Me」の研究開発を進めている。
今回、NTT版大規模言語モデル「tsuzumi」(※3)の拡張技術として、少量の対話データから個人の口調や発話内容の特徴を反映して対話を生成する個人性再現対話技術を開発。また、少量の音声データから個人の声色を反映した音声を合成するZero/Few-shot音声合成技術も併せて開発した。
従来、個人の特徴を学習し再現するには個人に関するデータが大量に必要だったのに対し、少量データから再現可能になったことで、多くの人が誰でも簡単にデジタル空間内に自身の分身を持つことが可能となる。
同社では発表に際して、「本研究成果の実用化に向けて、自分自身に代わって人とのコミュニケーションやコミュニティ活動などを行うデジタル分身の公開実証等を進めていきます」とコメントしている。
※1 IOWN 構想
あらゆる情報を基に個と全体との最適化を図り、光を中心とした革新的技術を活用し、高速大容量通信ならびに膨大な計算リソースなどを提供可能な、端末を含むネットワーク・情報処理基盤の構想。
https://www.rd.ntt/iown/
※2 地球・社会・個人間の調和的な関係が築かれる未来社会の実現に向けて~デジタルツインコンピューティングの4つの挑戦~
https://group.ntt/jp/newsrelease/2020/11/13/201113c.html
※3 NTT版大規模言語モデル「tsuzumi」
https://www.rd.ntt/research/LLM_tsuzumi.html
開発の背景
図1 Another Meのビジョン
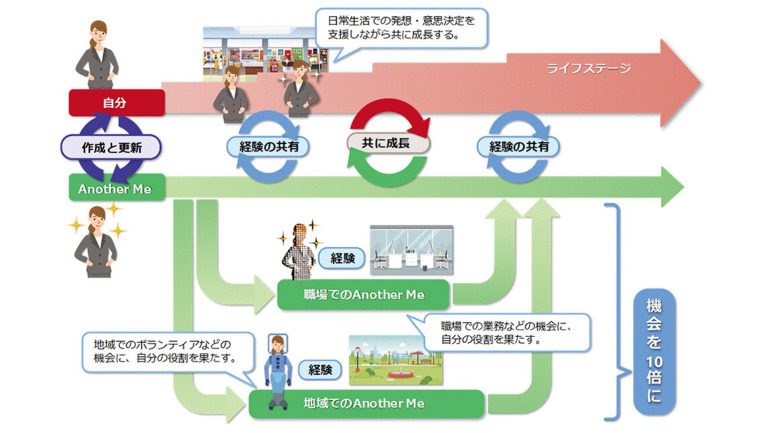 社会全体のデジタル化やAI技術の発展に伴い効率的な生活が実現されていく一方で、汎用AIのようなあらゆる問題に画一的な答えを出すAIへの過度な依存により、個人や社会の多様性が損なわれる可能性も指摘され始めている。
社会全体のデジタル化やAI技術の発展に伴い効率的な生活が実現されていく一方で、汎用AIのようなあらゆる問題に画一的な答えを出すAIへの過度な依存により、個人や社会の多様性が損なわれる可能性も指摘され始めている。
こうしたなかNTTでは、IOWN構想において人それぞれが多様な個性を自然に発揮できる社会の実現を目指しており、専門性や個性を備えた比較的小規模なAIの集合知による多様性の確保を方針としてNTT版大規模言語モデル「tsuzumi」の研究開発を進めてきた。
さらに、人の多種多様な個性を学習し人の代わりに自律的に活動するAIにより、人の多様性を様々な社会・経済活動に反映していくAnother Meプロジェクトを推進している。
本プロジェクトにおいて、昨年度は「過去の行動からその人が持つ趣味、価値観などを推定する個人性抽出技術」や「プロフィールや属性からその人らしい対話を再現する個人性再現対話技術」の開発(※4)を行なった。
今回、Another Meの社会実装をさらに進めるため、大規模言語モデル(LLM: Large Language Model)を対話に適用。さらに、少量のデータからでも高い本人再現性を実現する技術を開発した。
※4 NTTニュースリリース 2023年2月1日:人との繋がりを生み出す次世代アバターUX技術の開発~NTTドコモが技術提供するコミュニケーションサービスMetaMeに人デジタルツイン技術を試験実装~
https://group.ntt/jp/newsrelease/2023/02/01/230201a.html
個人性再現対話技術について
図2 従来技術と個人性再現対話技術の比較
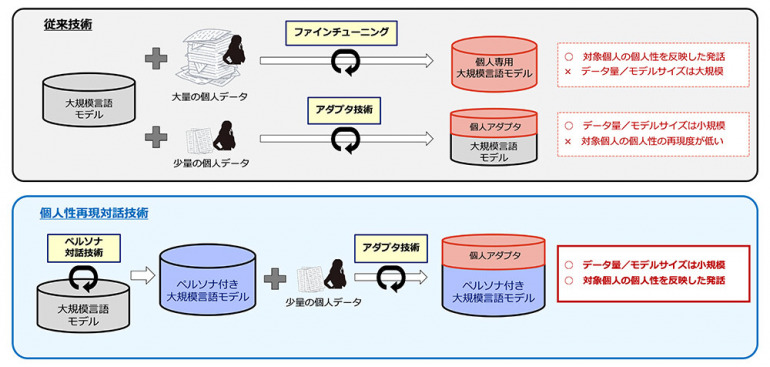 優れた文章生成能力を持つLLMは、対話を集めた大量のデータで学習させることで、雑談や議論など人の自然な会話を生成する対話技術にも適用が可能だ。
優れた文章生成能力を持つLLMは、対話を集めた大量のデータで学習させることで、雑談や議論など人の自然な会話を生成する対話技術にも適用が可能だ。
従来の対話技術の研究においては、個人性を再現するために個人の大量のデータでLLMをファインチューニング(※5)していたが、コストが高くAnother Meで目指す万人のデジタル分身の再現には適用できなかった。
これに対し、比較的少量のデータによりLLMを効率的に追加学習させる方法として、アダプタ技術(※6)がある。これを対話における個人性の再現に適用した場合、ベースとなるLLMが多種多様な人の大量のデータで学習されているため、少量のデータでは十分に学習が進まず、結果として特徴が全く異なる他人のような発話が生成され、個人の再現度が低下するという課題が生じていた(図2上)。
一方、個人性再現対話技術では、アダプタ技術にペルソナ対話技術(※7)を組み合わせることで、課題の解決を図っている。
ペルソナ対話技術によりベースとなるLLMにペルソナ機能を付加することで、LLMの応答が再現したい本人の大まかな個人性を反映するようになり、学習の初期状態がより本人に近づくため、少ないデータでも効率的な学習が可能になる。
また、生成段階においても、アダプタの学習データに含まれるものとは全く異なるような対話においても、ペルソナを反映した妥当な応答を返すことで、個人の再現性が高まる。
tsuzumiのアダプタ技術を個人性の再現に適用した個人アダプタは、エピソードを交えた発話や口癖など、対象の個人に特化した発話生成が可能。個人アダプタとして個人ごとに追加されるモデルのサイズは非常に小さく、動的に切り替えることができるため、多人数の対話の再現を効率的に実現できるという(図2下)。
※5 ファインチューニング: AIにデータに基づく知識を与えるための機械学習技術に関する用語で、大規模なデータで既に学習してあるAIモデルを、別の比較的小規模なデータで学習させて微調整(fine tuning)すること
※6 アダプタ技術: 事前学習済みモデルの外部に比較的小規模のモデル(アダプタ)を追加することで、事前学習済みモデルのパラメータを固定したまま効率的に追加学習が可能となる技術
NTT版大規模言語モデル「tsuzumi」 柔軟なチューニング ~基盤モデル+アダプタ~
https://www.rd.ntt/research/LLM_tsuzumi.html#anc03
※7 ペルソナ対話技術: ペルソナ対話技術は、対話データとともにプロフィールを学習させることでLLMにペルソナ機能を付加します。それにより、居住地や趣味などその人の大まかなプロフィール情報をパラメータ指定することで、そのようなプロフィールを持った人格(ペルソナ)に相応しい発話内容を再現することが可能。

