
















GPU は AI のトレーニングや推論においてトップクラスの性能を発揮
NVIDIAが同社ブログにおいて「GPUがAIに最適な理由」について解説するコンテンツを公開したので、本稿では、その概要を紹介していきたい。
GPUは、今日の生成AI 時代の基盤となっているため、人工知能のレア アース、あるいはゴールドとも呼ばれている。
以下の 3 つの技術的な理由と多くのエピソードがその理由を説明している。各理由には多角的な側面があり、探求する価値は十分で、かつ高水準だ。
・GPUは並列処理を採用
・スーパーコンピューティングの高みへとスケールアップしたGPUシステム
・幅広く深い AI のためのGPUソフトウェア スタック
これらの結果、GPUは CPUよりも高速かつ高いエネルギー効率で技術計算を実行する。つまり、GPUはAIのトレーニングや推論においてトップクラスの性能を発揮して、アクセラレーテッド コンピューティングを使用する幅広いアプリケーションで利益をもたらす。
スタンフォード大学の Human-Centered AIグループは、AIに関する最近の報告書の中で、いくつかの背景を説明している。GPUの性能は 2003 年以来「およそ 7000 倍向上し」、価格あたりの性能は「5600 倍」になったと報告した。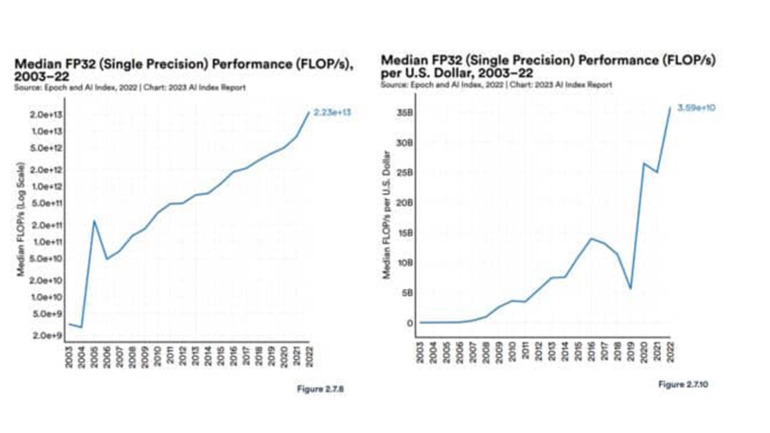 2023 年のレポートは、GPU の性能と性能/価格の急上昇を捉えている。
2023 年のレポートは、GPU の性能と性能/価格の急上昇を捉えている。
報告書はまた、AIの進歩を測定、予測する独立研究グループであるEpochの分析も引用している。
Epochはサイト上にて次のように述べている。
「GPUは、機械学習ワークロードを加速するための主要なコンピューティング プラットフォームです。すべてではないにしても、過去 5 年間における最大級モデルの大半は GPUでトレーニングされてきました。ですので、AIにおける最近の進歩に中心的に貢献しました」
米国政府向けの AI技術を評価した 2020年の調査でも、同様の結論が出ている。
「最先端 AI チップは、製造コストと運用コストを考慮すると、最先端ノード CPUよりも1~3桁コスト効率が高い」と予想している。
NVIDIA のチーフ サイエンティストである Bill Dally氏は、半導体およびシステム エンジニアが毎年集まる Hot Chips の基調講演にて、NVIDIA の GPU は、過去10年間で AI 推論のパフォーマンスを 1000 倍に向上させたと述べている。
ChatGPT がニュースを広める
ChatGPTは、GPUがいかにAIに適しているかを示す強力な例となった。何千ものNVIDIのGPUでトレーニングされ実行される大規模言語モデル (LLM) は、1 億人以上の人々が利用する生成 AIサービスを実行している。
2018年の発売以来、AIの業界標準ベンチマークである MLPerf は、AIのトレーニングと推論の両方におけるNVIDIA GPUの優れた性能を詳細に示す数値を提供してきた。
例えば、NVIDIA Grace Hopper Superchipは、推論テストの最新ラウンドを席巻した。そのテスト以降にリリースされた推論ソフトウェアであるNVIDIA TensorRT-LLMは、パフォーマンスを最大8倍向上させ、エネルギー使用量と総所有コストを5倍以上削減する。
実際、NVIDIA GPUは、ベンチマークが2019年にリリースされて以来、MLPerf のトレーニングと推論テストのすべてのラウンドで勝利している。
2 月には、NVIDIA GPUは、金融サービス業界にとって重要な技術性能指標である STAC-ML Marketsベンチマークにおいて、最も負荷の高いモデルで毎秒数千の推論を提供し、推論においてトップクラスの結果を出した。
RedHatのソフトウェア エンジニアリング チームはブログ内にて「GPUは人工知能の基盤になった」と簡潔に表現している。
■AI の裏側
GPUと AIがなぜ強力な組み合わせになるのか、その裏側を簡単に見てみたい。
ニューラルネットワークとも呼ばれる A モデルは、基本的に数学的なラザニアのようなもので、線形代数方程式を何層にも重ねたものだ。それぞれの方程式は、あるデータが別のデータに関連する可能性を表している。
GPUには何千ものコアが搭載されており、並列に動作する小さな計算機がAIモデルを構成する計算を切り分ける。これが、ハイレベルでの AI コンピューティングの仕組みだ。
■高度にチューニングされたTensorコア
長年の間、NVIDIAのエンジニアは、AIモデルの進化するニーズに合わせて GPUコアをチューニングしてきた。最新のGPUには、ニューラルネットワークが使用する行列計算を処理するための、第一世代よりも 60 倍強力な Tensor コアが含まれている。
さらに、NVIDIA H100 Tensor コアGPUには、生成 AIを生み出したニューラルネットワークの一種であるTransformerモデルの処理に必要な最適精度に自動的に調整されるTransformer Engineが搭載されている。
GPUは世代が進むにつれ、より多くのメモリを搭載し、AIモデル全体を単一のGPUまたはGPUセットに収める技術が最適化されてきた。
成長するモデル、拡大するシステム
AI モデルの複雑さは、1 年でなんと 10 倍に拡大している。
現在の最先端 LLMである GPT-4は、数学的密度の指標であるパラメーターを1兆個以上搭載している。これは、2018年に一般的だった LLMの 1 億以下のパラメーターから増加している。
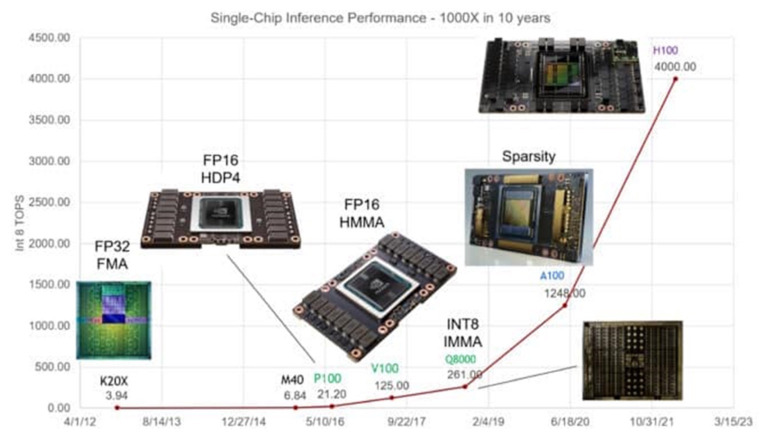
先日の Hot Chips での講演で、NVIDIA のチーフ サイエンティストである Bill Dally氏は、AI 推論におけるシングル GPU の性能が過去 10 年間で 1000 倍に拡大したことを説明した。
GPUシステムは、この課題に取り組むことで歩調を合わせてきた。高速な NVLink インターコネクトとNVIDIA Quantum InfiniBandネットワークのおかげで、GPUシステムはスーパーコンピューターにまでスケールアップする。
例えば、大規模メモリAI スーパーコンピューターである DGX GH200は、最大256 基のNVIDIA GH200 Grace Hopper Superchip を、144テラバイトの共有メモリを持つデータセンター サイズのシングルGPUに統合している。
各 GH200スーパーチップは、72 個のArm Neoverse CPUコアと 4 ペタフロップスのAI 性能を備えた 1 台のサーバーだ。新しい 4 Way Grace Hopper システム構成は、1 台のコンピュート ノードに 288個ものArmコアと16ペタフロップスのAI性能、最大2.3テラバイトの高速メモリを搭載している。
また、11月に発表された NVIDIA H200 Tensor コアGPU は、最大288ギガバイトの最新のHBM3eメモリ技術を搭載している。
■ソフトウェアがウォーターフロントをカバー
2007年以来、高度に専門的な機能から高度なアプリケーションまで、AIのあらゆる側面を可能にする GPUソフトウェアは大海原のように進化してきた。
NVIDIA AI プラットフォームには、何百ものソフトウェア ライブラリとアプリケーションが含まれている。ディープラーニングのための CUDAプログラミング言語とcuDNN-X ライブラリは、開発者が NVIDIA NeMo のようなソフトウェアを作成するための基盤を提供している。NVIDIA NeMo は、ユーザーが独自の生成 AI モデルを構築し、カスタマイズし、推論を実行するためのフレームワークだ。
これらの機能の多くは、ソフトウェア開発者の定番であるオープンソース ソフトウェアとして提供されている。完全なセキュリティとサポートを必要とする企業向けに、100 以上の機能が NVIDIA AI Enterpriseプラットフォームにパッケージ化されている。
また、NVIDIA DGX Cloud上のAPIやサービスとして、主要なクラウド サービス プロバイダから入手可能なケースも増えている。
SteerLMは、NVIDIA GPU向けの最新のAIソフトウェア アップデートの 1 つで、推論中にモデルをファインチューニングすることが可能だ。

