

















TCO とエネルギー効率の改善
データセンターにおける総所有コスト (TCO) とエネルギー消費の最小化は、AIを採用する顧客にとって重要な目標であり、特に LLM は計算要件が爆発的に増加するため、その重要性が増している。
顧客は、AI プラットフォームへの支出に関して、単一のサーバーのコストだけを見るわけではない。むしろ、設備投資コストと運用コストを総合的に見なければならない。
設備投資コストには、GPU サーバー、管理ヘッド ノード (すべての GPU サーバーを調整する CPU サーバー)、ネットワーク機器 (ファブリック、イーサネット、ケーブル配線)、ストレージのコストが含まれる。
運用コストには、データセンターの IT スタッフやソフトウェア、機器のメンテナンス、データセンターの賃料や電気代などが含まれる。データセンターで発生する実際のコストを全体的なレベルで見ると、大幅なパフォーマンスの高速化により、設備とメンテナンスの要件が削減され、資本と運用コストの大幅な節約につながる。
以下のチャートは、GPT-J 6B のような小規模な言語モデルで8倍の性能高速化を実現した場合、ベースラインの A100 と比較してTCOが5.3倍、エネルギー (電気代節約) が5.6倍削減されることを示している。
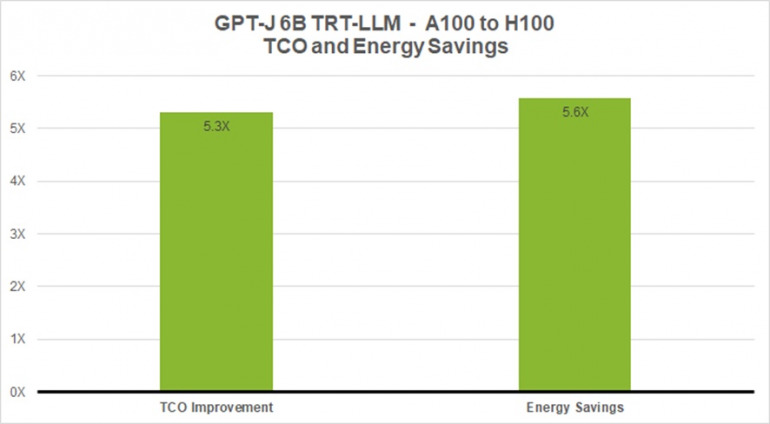 図3. GPT-J-6B、A100 と TensorRT-LLM を使用した H100 との比較
図3. GPT-J-6B、A100 と TensorRT-LLM を使用した H100 との比較
この棒グラフは、GPT-J-6B の性能を A100 と H100 の TCO とエネルギー ベネフィットで比較したものだ
同様に、Llama2 のような最先端の LLM では、700億のパラメータを使用した場合でも、ベースラインの A100 に対して 4.6 倍の性能高速化を実現し、TCO を 3 倍、消費エネルギーを 3.2 倍削減することが可能だ。
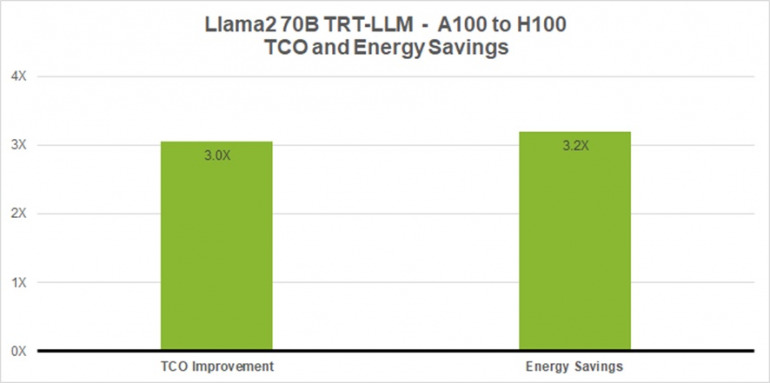 図4. Llama 2 70B、A100 と TensorRT-LLM を使用した H100 による TCO およびエネルギー コストの比較
図4. Llama 2 70B、A100 と TensorRT-LLM を使用した H100 による TCO およびエネルギー コストの比較
この棒グラフは、Llama 2 70B の性能を A100 と H100 の TCO およびエネルギーのメリットと比較したものだ
上記の TCO に加え、ソフトウェア開発には多額の人件費がかかり、これはインフラストラクチャのコストそのものを容易に上回る可能性がある。
NVIDIA が TensorRT、TensortRT-LLM、Triton Inference Server、および NeMo フレームワークに対して行った投資は、開発者の時間を大幅に節約し、市場投入までの時間を短縮する。
顧客は、全体の AI 支出を正確に把握するために、資本コストや運用コストを容易に上回る可能性のある、これらの人件費を考慮する必要がある。
LLM エコシステムの急増
エコシステムは急速に革新し、新しく多様なモデル アーキテクチャを開発している。より大規模なモデルは、新たな能力とユースケースを解き放つ。
Metaの700億パラメータを持つ Llama 2のような、最大かつ最先端の言語モデルの中には、リアルタイムで応答を返すために、複数のGPUが協調して動作する必要があるものもある。
以前は、LLMの推論で最高のパフォーマンスを達成しようとする開発者は、AIモデルを書き直して手作業で断片に分割し、複数のGPU 間で実行を調整する必要があった。
TensorRT-LLM は、個々の重み行列をデバイス間で分割するモデル並列の一種であるテンソル並列を使用する。これにより、開発者が介入したりモデルを変更することなく、NVLink を介して接続された複数の GPU や複数のサーバーで各モデルが並列に実行され、大規模で効率的な推論が可能になる。
新しいモデルやモデルアーキテクチャが導入されると、開発者は、TensorRT-LLM でオープンソースとして利用可能な最新の NVIDIA AI カーネルを使用して、モデルを最適化することができる。
サポートされるカーネル融合には、GPT モデル実行のコンテキストと生成フェーズ用の FlashAttention とマスクド マルチ ヘッド アテンションの最先端の実装など多くのものが含まれています。
さらに、TensorRT-LLM には、現在実運用で広く使用されている多くの LLM の完全に最適化された、すぐに実行できるバージョンが含まれています。これには、Meta Llama 2、OpenAI GPT-2 と GPT-3、Falcon、Mosaic MPT、BLOOM、その他多くの LLM が含まれており、これらはすべて、使いやすい TensorRT-LLM Python API で実装できる。
これらの機能により、開発者はカスタマイズされた LLM をより高速にかつ正確に作成し、事実上あらゆる業界のニーズに応えることが可能になる。
インフライト バッチング
今日の大規模言語モデルは、非常に汎用性が高い。1 つのモデルを、互いに全く異なる様々なタスクに同時に使用することができる。チャットボットでの単純な質疑応答から、文書の要約や長いコードの生成まで、ワークロードは非常に動的で、出力サイズは数桁異なってくる。
この多様性により、リクエストをバッチ処理し、効率的に並列実行することが難しくなることがある。これはニューラルネットワークを提供するための一般的な最適化だが、一部のリクエストが他のリクエストよりもはるかに早く終了してしまう可能もがある。
このような動的な負荷を管理するために、TensorRT-LLM には、インフライト バッチングと呼ばれる最適化されたスケジューリング テクノロジを備えている。これは、LLM の全体的なテキスト生成プロセスが、モデル上で実行される複数の反復に分割できるという事実を利用するものだ。
インフライト バッチングでは、バッチ全体が終了するのを待ってから次のリクエスト セットに移るのではなく、TensorRT-LLM ランタイムは、終了したシーケンスをバッチから即座に追い出していく。
そして、他のリクエストがまだ処理中に、新しいリクエストの実行を開始しする。インフライト バッチングと追加のカーネル レベルの最適化により、GPU 使用率が向上し、H100 Tensor コア GPU 上の実際の LLM リクエストのベンチマークでスループットが最低でも 2 倍になり、電力コストを削減、TCO を最小化するのに役立つ。
H100 Transformer Engine と FP8
LLM には何十億ものモデルの重みと活性化が含まれており、通常、各値が 16 ビットのメモリを占有する 16 ビット浮動小数点 (FP16 または BF16) の値でトレーニング、表現される。
しかし推論時には、最新の量子化技術を使えば、ほとんどのモデルは 8 ビットや 4 ビット整数 (INT8 や INT4) のような低い精度で効率的な表現が可能だ。
量子化とは、正確度を犠牲にすることなく、モデルの重みと活性化の精度を下げるプロセス。精度を下げるということは、各パラメータが小さくなり、モデルが GPU メモリに占めるスペースが小さくなることを意味する。これにより、同じハードウェアでより大きなモデルの推論が可能になると同時に、実行中のメモリ操作に費やす時間を減らすことができる。
TensorRT-LLM を使用した NVIDIA H100 GPU は、モデルの重みを新しい FP8 フォーマットに簡単に変換し、最適化された FP8 カーネルを利用するためにモデルを自動的にコンパイルする機能を提供する。
これは、Hopper Transformer Engine テクノロジによって可能になり、モデル コードを変更することなく実行できる。
H100 で導入された FP8 データ フォーマットにより、開発者はモデルの正確度を落とすことなくモデルを量子化し、メモリ消費量を根本的に削減することが可能だ。
FP8 量子化は、INT8 や INT4 のような他のデータ フォーマットと比較して高い正確度を維持しながら、最速のパフォーマンスを達成し、最もシンプルな実装を提供できる。
概要
LLM は急速な進歩を遂げている。多様なモデル アーキテクチャが日々開発され、成長するエコシステムに貢献している。そして、より大規模なモデルは、新たな機能とユースケースを解放し、あらゆる産業での採用を促進している。
LLM の推論はデータセンターを再構築している。より高い正確度でより高いパフォーマンスを実現することは、企業にとってより良い TCO をもたらすはずだ。モデルの革新は、より良い顧客体験を可能にし、収益と利益の向上につながってくる。
推論展開プロジェクトを計画する際、最先端の LLM を使って最高のパフォーマンスを達成するためには、他にも多くの考慮すべき事項がある。最適化が自動的に行われることは稀だ。
ユーザーは、並列性、エンドツーエンドのパイプライン、高度なスケジューリング テクノロジなどの調整要素を考慮しなければならず、また正確度を落とすことなく、混合精度を扱えるコンピューティング プラットフォームが必要だ。
TensorRT-LLM は、TensorRT のディープラーニング コンパイラ、最適化されたカーネル、プリ ポスト処理、マルチ GPU/マルチノード通信で構成され、シンプルでオープンソースの Python API で、実運用での推論のために LLM を定義、最適化、実行することができる。
TensorRT-LLM の使用方法
NVIDIA TensorRT-LLM は現在、早期アクセスで利用可能となっており、間もなく NVIDIA NeMo フレームワーク (セキュリティ、安定性、管理性、サポートを備えたエンタープライズ グレードの AI ソフトウェア プラットフォームである NVIDIA AI Enterprise の一部) に統合される。
開発者や研究者は、NGC の NeMo フレームワークまたは GitHub のソース リポジトリから TensorRT-LLM にアクセスできるようになる。
※早期アクセス リリースに参加するには、NVIDIA Developer Program への登録が必要です。また、組織のメール アドレスを使用してログインする必要があります。Gmail、Yahoo、QQ などの個人的なメール アカウントからの申請は受け付けられません。
構成/清水眞希

