

















大規模言語モデルは驚くべき新機能を提供し、AI で実現できる領域を拡大している。しかし、その大きなサイズと特有の実行特性は、費用対効果の高い方法で使用することを困難にすることがある。
そこでNVIDIA はMeta、AnyScale、Cohere、Deci、Grammarly、Mistral AI、MosaicML (現在は Databricks の一部)、OctoML、ServiceNow、Tabnine、Together AI、Uberなどの主要な企業と緊密に協力しながら、LLM の推論の高速化と最適化に取り組んできた。
これらのイノベーションはオープンソースの NVIDIA TensorRT-LLM ソフトウェアに統合され、Ampere、Lovelace、Hopper GPU に対応し、数週間以内にリリースされる予定だ。
TensorRT-LLM は、TensorRT ディープラーニング コンパイラで構成され、NVIDIA GPU 上で画期的なパフォーマンスを発揮するために最適化されたカーネル、プリ ポスト処理ステップ、およびマルチ GPU/マルチノードの通信プリミティブが含まれている。開発者は、C++ や NVIDIA CUDA の深い知識を必要とすることなく、最高のパフォーマンスと迅速なカスタマイズ機能を提供する新しい LLM を試すことができる。
TensorRT-LLM は、オープンソースのモジュラー Python API によって使いやすさと拡張性を向上させ、LLM の進化に合わせて新しいアーキテクチャと拡張機能を定義、最適化、実行し、簡単にカスタマイズすることが可能だ。
例えば、MosaicML は、TensorRT-LLM の上に必要な特定の機能をシームレスに追加し、推論サービスに統合した。Databricksのエンジニアリング担当バイス プレジデントである Naveen Rao氏は次のように述べている。
「それはまったく簡単なことでした。TensorRT-LLM は使いやすく、トークンのストリーミング、インフライト バッチング、ページ アテンション、量子化などの機能が満載で、効率的です。TensorRT-LLM は、NVIDIA GPU を使用した LLM のサービスに最先端のパフォーマンスを提供し、コスト削減を顧客に還元できるようになります」
性能比較
記事の要約は、LLM の多くのアプリケーションの 1 つに過ぎない。以下のベンチマークは、最新の NVIDIA Hopper アーキテクチャ上で TensorRT-LLM によってもたらされるパフォーマンスの向上を示している。
以下の図は、NVIDIA A100 と NVIDIA H100 を使用し、要約性能の評価用データセットとしてよく知られている CNN/Daily Mail を用いた記事要約のパフォーマンスを表したものだ。
図1では、H100のみの場合は、A100 より4倍高速だ。TensorRT-LLM とインフライト バッチングを含むその利点が加わると、パフォーマンスは合計で8倍に向上し、最高のスループットを実現する。
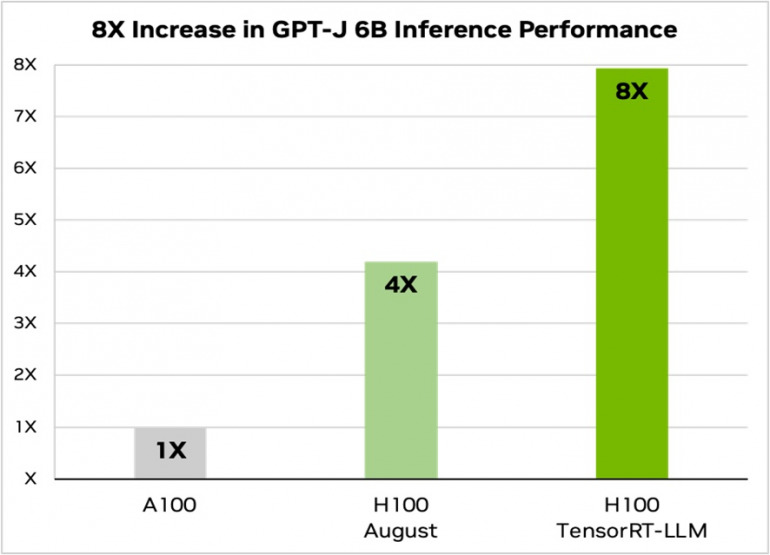 図1. GPT-J-6B、A100 と H100 の TensorRT-LLM の有無による比較
図1. GPT-J-6B、A100 と H100 の TensorRT-LLM の有無による比較
テキスト要約、可変 I/O 長、CNN / DailyMail データセット | A100 FP16 PyTorch Eager モード | H100 FP8 | H100 FP8、インフライト バッチング、TensorRT-LLM
Llama 2 は、Metaが最近リリースした言語モデルであり、生成 AI の導入を検討している企業で広く使用されている。TensorRT-LLM は A100 GPU と比較して推論性能を 4.6倍高速化できる。
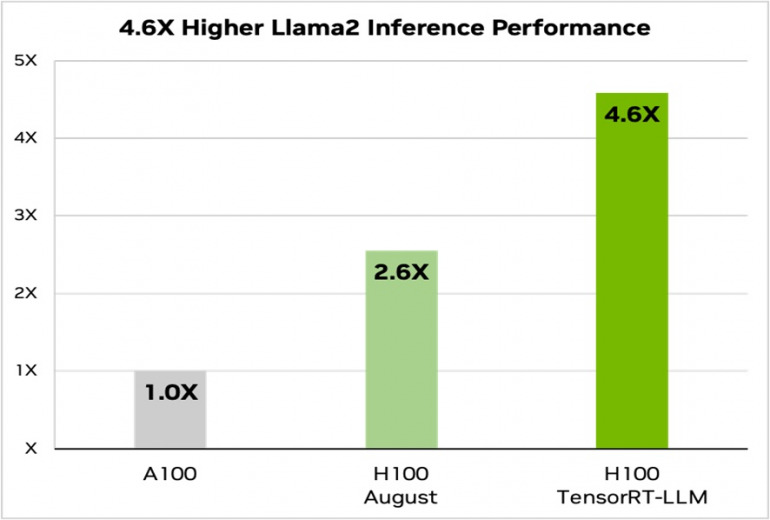 図 2. Llama 2 70B、A100 と H100 の TensorRT-LLM の有無による比較
図 2. Llama 2 70B、A100 と H100 の TensorRT-LLM の有無による比較
テキスト要約、可変 I/O 長、CNN / DailyMail データセット | A100 FP16 PyTorch Eager モード | H100 FP8 | H100 FP8、インフライト バッチング、TensorRT-LLM

