
















生成AIは機械学習を新たな高みへと押し上げ、アイデアの豊富なパイプラインを生み出した
 去る8月27日から8月29日まで開催された次世代プロセッサーの最新情報や技術が公開される「Hot Chips 2023」において、NVIDIAのチーフ サイエンティスト兼リサーチ担当シニア バイス プレジデントであるBill Dally (ビル ダリー) 氏が基調講演に登壇。
去る8月27日から8月29日まで開催された次世代プロセッサーの最新情報や技術が公開される「Hot Chips 2023」において、NVIDIAのチーフ サイエンティスト兼リサーチ担当シニア バイス プレジデントであるBill Dally (ビル ダリー) 氏が基調講演に登壇。
ハードウェア性能の劇的な向上が生成 AI を生み出し、機械学習を新たな高みへと押し上げる将来の高速化に関するアイデアの豊富なパイプラインを生み出したと述べた。
ダリー氏はこの講演の中で、現在開発中の技術の数々について説明しているので、本稿ではその概要をお伝えする。
世界有数のコンピューター科学者で、スタンフォード大学コンピューターサイエンス学部の前学長であるダリー氏は次のように述べた。
「AI の進歩は目覚ましく、それはハードウェアによって実現されたものですが、依然としてディープラーニングのハードウェアによって制限されています」
例えば、数百万人が使用している大規模言語モデル (LLM) である ChatGPT が、自分のトークのアウトラインをどのように提案できるかを示した。このような機能は、過去10年間のGPU によるAI 推論性能の向上によるところが大きいと、ダリー氏は指摘する。
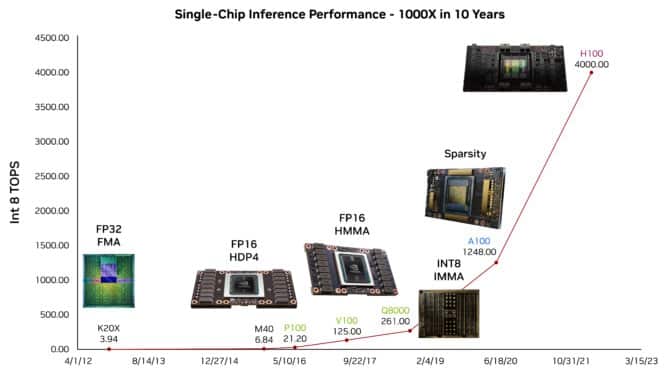
シングルGPUの性能向上は、データセンター規模のスーパーコンピューターへの拡張における100万倍もの進歩を含む、より大きなストーリーの一部に過ぎない。
100TOPS / ワットを実現する研究
研究者たちは次の進歩の波を準備している。ダリー氏は、LLMで1ワットあたり100 TOPS近くを実証したテスト チップについて説明した。
この実験では、生成 AI で使われる Transformer モデルをさらに高速化するエネルギー効率の良い方法が示された。実験においては、将来的な発展が期待されるいくつかの簡略化された数値計算アプローチのひとつである 4 ビット演算が適用された。

ビル・ダリー氏
ダリー氏は、NVIDIAが2021年に特許を取得した、対数計算を用いた計算の高速化とエネルギーを節約する方法について議論した。
AI用ハードウェアの調整
彼は新しいデータ型や演算を定義することで、ハードウェアを特定の AIタスクに適合させるための 6 つのテクニックを紹介した。
そしてNVIDIA A100 Tensor コア GPU で初めて採用された構造的スパース性と呼ばれるアプローチで、シナプスとニューロンを刈り込み、ニューラルネットワークを単純化する方法について次のように説明。
「スパース性はまだ終わっていません。アクティベーションをどうにかする必要があり、ウェイトにも大きなスパース性を持たせることができます」
研究者は、ハードウェアとソフトウェアを連動させて設計し、貴重なエネルギーをどこに使うかを慎重に決定する必要がある、とダリー氏は言う。例えば、メモリや通信回路は、データの移動を最小限に抑える必要がある。
「コンピューター エンジニアであるのが楽しい時期です。私たちは AI の大革命を可能にしており、それがどれほど大きな革命になるのか、まだ完全に理解さえしていないのです」
より柔軟なネットワーク
別の講演では、NVIDIA のネットワーキング担当バイス プレジデントである Kevin Deierling (ケビン ディアリング) 氏が、変化するネットワーク トラフィックやユーザー ルールに基づいてリソースを割り当てるための NVIDIA BlueField DPU と NVIDIA Spectrum ネットワーキング スイッチのユニークな柔軟性について説明した。
ハードウェア アクセラレーション パイプラインを数秒で動的にシフトするチップの能力は、最大スループットでの負荷分散を可能にし、コア ネットワークに新たなレベルの適応性を与えます。これは、サイバーセキュリティの脅威から身を守るために特に有効だ。
ディアリング氏は次のように述べている。
「今日、生成 AI ワークロードやサイバーセキュリティでは、すべてが動的であり、絶えず変化しています。だから私たちは、ランタイムのプログラマビリティと、その場で変更可能なリソースに移行しているのです」
さらに、NVIDIA とライス大学の研究者は、人気の高いP4プログラミング言語を使用して、ユーザーがランタイムの柔軟性を活用する方法を開発している。
Grace がサーバー CPU をリード
Arm による Neoverse V2 コアに関する講演では、Neoverse V2 コアを実装した最初のプロセッサである NVIDIA Grace CPU Superchip の性能に関する最新情報が紹介されました。
テストによると、同じ消費電力で、Grace システムは、さまざまな CPU ワークロードにわたって、現在の x86 サーバーよりも最大2倍のスループットを提供する。
さらに、ArmのSystemReady Programは、Graceシステムが既存の Arm オペレーティング システム、コンテナ、アプリケーションを変更なしで実行できることを認証している。
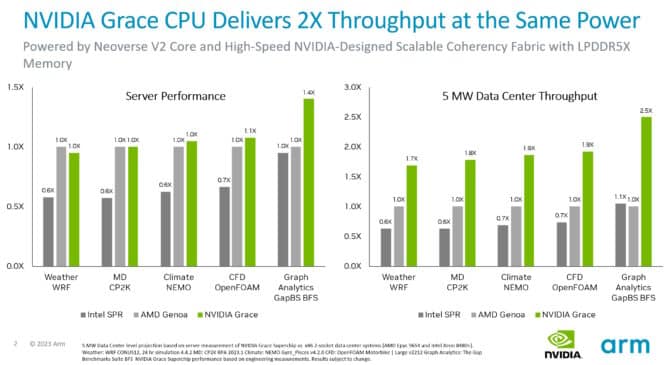
Graceは、データセンター事業者により高いパフォーマンスを提供するか、より少ない電力を使用するかの選択肢を提供する。
Grace は、超高速のファブリックを使用して、1 つのダイに72個のArm Neoverse V2コアを接続する。NVLink がこれらのダイを2 つ接続し、毎秒 900GBの帯域幅を実現。
また、サーバークラスの LPDDR5X メモリを採用する初のデータセンター向け CPUであり、一般的なサーバー用メモリの8分の1の消費電力で、同程度のコストで50% 以上多いメモリ帯域幅を提供する。
関連情報
https://blogs.nvidia.co.jp/2023/09/06/hot-chips-dally-research/
構成/清水眞希

