

















NVIDIAは、同社主催のAIカンファレンス「NVIDIA GTC」にて、全世界の企業が大規模言語モデル(LLM)を開発および導入し、自社の領域に焦点を当てたチャットボット、パーソナルアシスタント、ならびに微妙な表現やニュアンスを前例のないレベルで理解できるAIアプリケーションを構築できるようにすることを発表した。
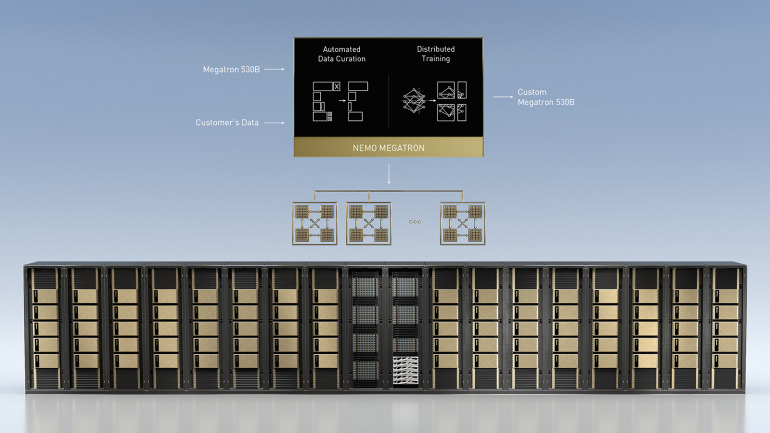
NVIDIAは、数兆のパラメータを持つ言語モデルをトレーニングするためのNVIDIA NeMo Megatronフレームワーク、新しい領域や言語に合わせたトレーニングができるカスタマイズ可能なLLMであるMegatron 530B、およびマルチGPUかつマルチノードの分散推論機能を備えたNVIDIA Triton Inference Serverを公開。
NVIDIA DGXシステムと組み合わせることにより、これらのツールは大規模言語モデルの開発と導入を簡素化する、プロダクションレディなエンタープライズグレードのソリューションとなるという。
NVIDIAのディープラーニング応用研究担当バイスプレジデントのブライアン・カタンザーロ (Bryan Catanzaro) は、「大規模言語モデルは柔軟で、高い能力を持っており、専門的な質問への回答、言語の翻訳、文書の把握と要約、ストーリーの執筆やコンピュータープログラムの生成といったことをすべて、特殊なトレーニングや教師なしでできることが証明されています。新しい言語および分野のための大規模言語モデルの構築は、最大級のスーパーコンピューティングアプリケーションと言えますが、現在では、これを実現するための性能を世界中の企業が手に入れられるようになっています」と述べている。
関連情報
https://www.nvidia.com/ja-jp/
構成/立原尚子

